library(liver)
data(house, package = "liver")
str(house)
'data.frame': 414 obs. of 6 variables:
$ house_age : num 32 19.5 13.3 13.3 5 7.1 34.5 20.3 31.7 17.9 ...
$ distance_to_MRT: num 84.9 306.6 562 562 390.6 ...
$ stores_number : int 10 9 5 5 5 3 7 6 1 3 ...
$ latitude : num 25 25 25 25 25 ...
$ longitude : num 122 122 122 122 122 ...
$ unit_price : num 37.9 42.2 47.3 54.8 43.1 32.1 40.3 46.7 18.8 22.1 ...10 Regression Analysis: Linear and Nonlinear Models
Everything should be made as simple as possible, but not simpler.
How can housing prices be predicted from a home’s age, location, and nearby amenities? How can a bike-sharing system estimate hourly rental demand from weather conditions and time-related patterns? Questions such as these lie at the heart of regression analysis, one of the most widely used tools in data science. Regression models help us describe how a numerical outcome changes in relation to one or more predictors, quantify the strength of those relationships, and generate predictions based on observed data.
The roots of regression analysis go back to the late nineteenth century, when Francis Galton introduced the term regression in the study of heredity. Its mathematical foundations were later formalized through the method of least squares, which remains central to linear regression today. Over time, regression developed into a core framework for statistical modeling, supporting both explanation and prediction across fields such as economics, medicine, engineering, and business analytics.
Regression is powerful precisely because it serves more than one goal. In some applications, we want to explain how predictors are associated with an outcome and assess whether those associations are statistically meaningful. In others, the main goal is prediction: given a set of predictor values, how accurately can we estimate a future or unseen response? In practice, good regression modeling often requires balancing these two aims while also checking whether the fitted model is appropriate for the data.
In this chapter, we build on the Data Science Workflow introduced in Chapter 2 and illustrated in Figure 2.1. Earlier chapters focused on data preparation, exploratory analysis, and classification methods such as k-Nearest Neighbors (Chapter 7) and Naive Bayes (Chapter 9), together with tools for evaluating predictive performance (Chapter 8). Regression extends this workflow to supervised learning problems in which the response variable is continuous, allowing us to study both prediction and interpretation within a common modeling framework.
This chapter also connects directly to the statistical foundations developed in Chapter 5, particularly the discussion of correlation and inference in Section 5.13. Regression builds on these ideas by modeling relationships explicitly, allowing multiple predictors to be considered simultaneously, and providing a framework for testing whether individual predictors contribute meaningfully once the others are taken into account.
What This Chapter Covers
This chapter introduces regression analysis as a core modeling framework within the data science workflow. While earlier chapters focused mainly on classification problems, regression addresses tasks in which the outcome variable is numeric and continuous, such as price, cost, demand, or revenue.
We begin with simple linear regression to develop the basic ideas of model fitting, coefficient interpretation, and prediction. We then extend these ideas to multiple regression, where several predictors are considered simultaneously. Along the way, we examine how to assess model quality using measures such as the residual standard error, \(R^2\), and adjusted \(R^2\), and how to interpret regression coefficients in light of both statistical significance and practical relevance.
Regression is useful not only for prediction, but also for understanding how predictors are associated with an outcome. For that reason, the chapter emphasizes both perspectives. Some sections focus on explanation and inference, while others focus more directly on predictive performance and model comparison.
Many real-world relationships are not strictly linear. To address this, we introduce polynomial regression as a practical extension that allows curved relationships to be modeled while preserving the familiar linear modeling framework. We also examine model refinement through stepwise regression and show how diagnostic tools such as residual plots can help us assess assumptions, identify potential problems, and improve the model when needed.
Throughout the chapter, we use the real-world house dataset to illustrate how regression models are built, interpreted, compared, and diagnosed in practice. In the final section, we bring these ideas together in a case study on hourly bike rental demand using the bike_demand dataset.
By the end of this chapter, you will be able to fit, interpret, compare, and critically evaluate regression models in R, judge whether linear assumptions are reasonable, and extend regression models to capture more complex relationships when needed. We begin with simple linear regression, which provides the foundation for the rest of the chapter.
10.1 Simple Linear Regression
Simple linear regression is the natural starting point for regression modeling. It provides a formal way to study the relationship between a single predictor and a numerical response. By focusing on one predictor at a time, we develop intuition for how regression models are fitted, how coefficients are interpreted, and how predictions are made before extending these ideas to models with several predictors.
To illustrate these ideas, we use the house dataset from the liver package. This dataset contains house-level information together with a numerical response, unit_price, making it well suited for studying how individual housing characteristics are associated with price.
We begin by loading the dataset and inspecting its structure:
The dataset contains 414 observations and 6 variables. From the output of str(house), we can identify the response variable, unit_price, together with several numerical predictors. In this chapter, we begin by examining how one predictor at a time relates to the response, and then later extend the analysis to multiple regression.
Before fitting a regression model, it is useful to examine how the response variable relates to the available predictors. This helps us identify promising candidate predictors, assess whether a linear relationship seems plausible, and detect unusual patterns that may matter for modeling. Figure 10.1 presents a matrix of pairwise relationships among the numeric variables in the house dataset using the pairs.panels() function from the psych package. The upper triangle shows correlation coefficients, the lower triangle shows scatter plots, and the diagonal displays histograms.
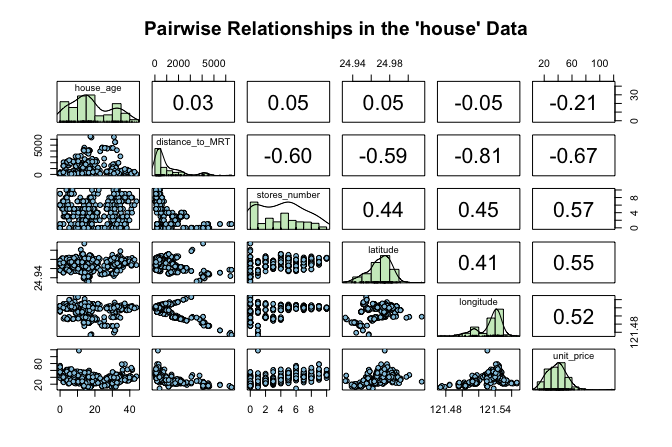
house dataset. The upper triangle shows correlation coefficients, the lower triangle shows scatter plots, and the diagonal displays histograms.
This matrix gives an initial sense of which predictors are associated with unit_price and whether those relationships appear roughly linear. It also helps us detect possible outliers or unusual patterns. Among the available predictors, stores_number shows a clear positive association with house price and provides a natural starting point for simple linear regression. This exploratory step also connects to the discussion of correlation in Section 5.13, where we introduced linear association as a descriptive concept. We now move from description to modeling.
Fitting a Simple Linear Regression Model
We begin by modeling the relationship between the number of nearby stores (stores_number) and house unit price (unit_price). This example is easy to interpret while still illustrating the core ideas of regression.
Before fitting the model, it is helpful to visualize the relationship between the predictor and the response. A scatter plot with a fitted regression line provides a first indication of whether a linear model offers a reasonable description of the data.
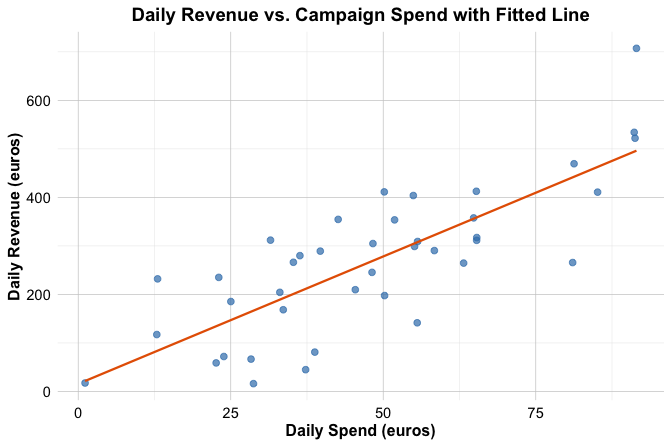
Figure Figure 10.2 suggests a positive association: houses with more nearby stores tend to have higher unit prices. The overall pattern appears roughly linear, which motivates fitting a simple linear regression model.
We represent this relationship as \[
\hat{y} = b_0 + b_1 x,
\] where \(\hat{y}\) is the predicted value of the response variable (unit_price), \(x\) is the predictor (stores_number), \(b_0\) is the intercept, and \(b_1\) is the slope. The slope \(b_1\) represents the expected change in unit price associated with a one-unit increase in the number of nearby stores.
To build intuition, Figure 10.3 gives a conceptual illustration of the model. The fitted regression line summarizes the overall linear pattern in the data, while the vertical distance between an observed value \(y_i\) and its predicted value \(\hat{y}_i = b_0 + b_1 x_i\) is called a residual. Residuals represent the part of the response that is not explained by the model.

Fitting the Simple Regression Model in R
Having introduced the model conceptually, we now estimate it in R using the lm() function. This base R function fits linear models and will be used throughout the chapter. Its basic syntax is
lm(response_variable ~ predictor_variable, data = dataset)In our example, we model house unit price as a function of the number of nearby stores:
simple_reg <- lm(unit_price ~ stores_number, data = house)We can inspect the fitted model using summary():
summary(simple_reg)
Call:
lm(formula = unit_price ~ stores_number, data = house)
Residuals:
Min 1Q Median 3Q Max
-35.407 -7.341 -1.788 5.984 87.681
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 27.1811 0.9419 28.86 <2e-16 ***
stores_number 2.6377 0.1868 14.12 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 11.18 on 412 degrees of freedom
Multiple R-squared: 0.326, Adjusted R-squared: 0.3244
F-statistic: 199.3 on 1 and 412 DF, p-value: < 2.2e-16The fitted regression equation is \[ \widehat{\text{unit\_price}} = 27.18 + 2.64 \times \text{stores\_number}. \]
The intercept (\(b_0\)) represents the estimated unit price for a house with zero nearby stores, while the slope (\(b_1\)) represents the expected change in unit price associated with one additional nearby store. In this model, the estimated slope indicates that each additional nearby store is associated with an average increase of approximately 2.64 in unit price.
The summary() output also reports standard errors, test statistics, p-values, the residual standard error, and measures of overall model fit. These quantities help us assess both the strength of the evidence for a linear relationship and how well the model describes the data. We return to these ideas later in the chapter.
Taken together, the results suggest that stores_number is a useful predictor of unit_price in this dataset. The fitted model now provides a basis for prediction and for deeper interpretation of regression output.
Practice: Repeat the modeling steps in this subsection using
distance_to_MRTas the predictor instead ofstores_number. Fit a simple linear regression model withunit_priceas the response variable anddistance_to_MRTas the predictor, and examine the estimated intercept and slope. Use thesummary()output to assess whether the relationship appears statistically meaningful and to interpret the estimated slope in context.
Making Predictions with the Regression Line
One of the main uses of a fitted regression model is prediction. Once the relationship between the number of nearby stores and house unit price has been estimated, the regression line can be used to predict the expected unit price for a given number of stores.
Suppose we want to estimate the expected unit price for a house located near 5 stores. Using the fitted regression equation, we obtain \[ \widehat{\text{unit\_price}} = b_0 + b_1 \times 5 = 27.18 + 2.64 \times 5 = 40.37. \]
The model therefore predicts an expected unit price of approximately 40.37 when the number of nearby stores is 5. This is a predicted average value for houses with that predictor value, not a guarantee of the exact unit price for any particular house.
Predictions are generally most reliable when the predictor values fall within the observed range of the data and when the model assumptions are reasonably satisfied. Predictions far outside the observed range involve extrapolation and should be interpreted with caution. The differences between observed and predicted values are called residuals, and we return to them later when discussing model fit.
In practice, we usually generate predictions in R with the predict() function rather than by substituting values into the regression equation by hand:
round(predict(simple_reg, newdata = data.frame(stores_number = 5)), 2)
1
40.37We can also generate predictions for several values at once:
round(predict(simple_reg, newdata = data.frame(stores_number = c(1, 3, 8))), 2)
1 2 3
29.82 35.09 48.28Later in the chapter, we will distinguish more carefully between estimating an average response and predicting a new observation. For now, the key point is that the fitted regression line gives us a practical way to translate predictor values into expected outcomes.
Predictions are one of the main uses of regression models, but they are not the only one. In the next section, we extend these ideas from a single predictor to several predictors, leading to multiple linear regression.
10.2 Multiple Linear Regression
We now extend simple linear regression to settings with more than one predictor. This leads to multiple linear regression, a framework that allows us to model a numerical response using several predictors simultaneously. In practice, outcomes are rarely determined by a single factor, so multiple regression provides a more realistic way to study how predictors relate to the response.
In the house dataset, house price is likely influenced by more than just the number of nearby stores. Age, distance to public transport, and location may all matter as well. Multiple regression allows us to examine how each predictor is associated with unit_price while accounting for the others. This is one of its main advantages: it helps us move from isolated pairwise relationships to a model that reflects several relevant factors at once.
The general form of a multiple regression model with \(m\) predictors is \[ \hat{y} = b_0 + b_1 x_1 + b_2 x_2 + \dots + b_m x_m, \] where \(b_0\) is the intercept and \(b_1, b_2, \dots, b_m\) are the estimated coefficients. Each coefficient represents the expected change in the response associated with a one-unit increase in the corresponding predictor, while holding the other predictors fixed. This conditional interpretation is what distinguishes multiple regression from simple regression, where the effect of a predictor is considered on its own.
Fitting and Interpreting a Multiple Regression Model in R
To fit a multiple regression model in R, we again use the lm() function. The main difference is that we now include several predictors on the right-hand side of the formula. If we want to use all remaining variables in the dataset as predictors, we can use the shorthand .:
full_model <- lm(unit_price ~ ., data = house)
summary(full_model)
Call:
lm(formula = unit_price ~ ., data = house)
Residuals:
Min 1Q Median 3Q Max
-34.546 -5.267 -1.600 4.247 76.372
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -4.946e+03 6.211e+03 -0.796 0.426
house_age -2.689e-01 3.900e-02 -6.896 2.04e-11 ***
distance_to_MRT -4.259e-03 7.233e-04 -5.888 8.17e-09 ***
stores_number 1.163e+00 1.902e-01 6.114 2.27e-09 ***
latitude 2.378e+02 4.495e+01 5.290 2.00e-07 ***
longitude -7.805e+00 4.915e+01 -0.159 0.874
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 8.965 on 408 degrees of freedom
Multiple R-squared: 0.5712, Adjusted R-squared: 0.5659
F-statistic: 108.7 on 5 and 408 DF, p-value: < 2.2e-16This model uses all remaining variables in the house dataset to explain unit_price. The dot notation is a convenient way to fit a full regression model without listing each predictor explicitly.
The summary() output reports an estimated coefficient for each predictor, together with its standard error, test statistic, and p-value. These quantities help us assess how each predictor is associated with unit_price once the others are taken into account.
This conditional interpretation is important. In simple regression, the coefficient of stores_number described how unit_price changes when stores_number is considered alone. In multiple regression, the coefficient of stores_number describes how unit_price changes with stores_number after adjusting for the other predictors in the model. As a result, the coefficient may differ from the one obtained in the simple regression model.
In practice, predictions from a multiple regression model are usually generated with the predict() function rather than by manually evaluating the fitted equation. This is especially useful when several predictors are involved. We return to prediction later in the chapter, particularly in the case study, where fitted regression models are used to predict hourly bike rental demand.
Multiple regression therefore allows us to explain variation in unit_price using several predictors at once, rather than relying on a single explanatory variable. In the next section, we compare the simple and multiple regression models more formally using measures such as the residual standard error, \(R^2\), and adjusted \(R^2\).
Practice: Compare the coefficient of
stores_numberin the simple regression model with its coefficient in the multiple regression model. How does the interpretation change once the other predictors are included?
A Note on Simpson’s Paradox
As we move from simple regression to multiple regression, it is important to remember that relationships can change once additional variables are taken into account. A classic example of this is Simpson’s Paradox, where an association observed in aggregated data weakens, disappears, or even reverses after the data are separated into meaningful groups.
Figure Figure 10.4 illustrates this idea. The left panel shows a regression line fitted to the full dataset, ignoring group structure. The right panel shows separate fitted lines within groups. Although the overall trend appears negative in the aggregated data, the within-group relationships are positive.

This idea is relevant for the house data as well. The coefficient of stores_number in the simple regression model does not necessarily match its coefficient in the multiple regression model, because the latter is interpreted after adjusting for the other house characteristics. More generally, apparent associations can change once relevant variables are included in the model.
10.3 Measuring Model Fit in Regression
After fitting both a simple regression model and a multiple regression model, an important next question is how to judge which model provides a better fit to the data. The multiple regression model includes all available predictors in the house dataset and is therefore more complex than the simple regression model, which uses only stores_number. But does this added complexity improve the model in a meaningful way?
To address this question, we use summary measures of model fit. In this section, we focus on three widely used quantities: the residual standard error (RSE), which summarizes the typical size of the residuals; the coefficient of determination, \(R^2\), which measures the proportion of variability explained by the model; and adjusted \(R^2\), which modifies \(R^2\) to account for model complexity. Together, these measures help us compare the simple and multiple regression models and assess whether the added predictors lead to a meaningful improvement in fit.
Residual Standard Error
To understand model fit, we begin with the idea of a residual. A residual is the difference between an observed response value and the corresponding value predicted by the model. For observation \(i\), the residual is \[ e_i = y_i - \hat{y}_i, \] where \(y_i\) is the observed value and \(\hat{y}_i\) is the fitted value from the regression model. Residuals therefore represent the part of the response that remains unexplained after the model is fitted.
The regression line or regression surface is estimated by choosing the coefficients that make the residuals as small as possible overall. More precisely, least squares estimation minimizes the sum of squared residuals, also called the sum of squared errors: \[ \text{SSE} = \sum_{i=1}^{n} (y_i - \hat{y}_i)^2. \tag{10.1}\]
A smaller SSE indicates that the fitted values lie closer to the observed values. However, because SSE depends on the number of observations and the scale of the response, it is not always easy to interpret directly. For this reason, we often use the residual standard error (RSE), which summarizes the typical size of the residuals on the scale of the response variable.
The RSE is defined as \[ RSE = \sqrt{\frac{SSE}{n - m - 1}}, \] where \(n\) is the number of observations and \(m\) is the number of predictors. The denominator \(n - m - 1\) reflects the model’s degrees of freedom. In simple linear regression, where \(m = 1\), this becomes \(n - 2\) because both the intercept and slope are estimated from the data.
A smaller RSE indicates that, on average, the fitted values lie closer to the observed values. For the simple and multiple regression models fitted to the house dataset, the RSE values can be computed directly as follows:
rse_simple <- sqrt(sum(simple_reg$residuals^2) / summary(simple_reg)$df[2])
rse_multiple <- sqrt(sum(full_model$residuals^2) / summary(full_model)$df[2])
round(c(rse_simple = rse_simple, rse_multiple = rse_multiple), 2)
rse_simple rse_multiple
11.18 8.96These are the same RSE values reported in the summary(simple_reg) and summary(full_model) outputs. Computing them directly helps clarify how the residual standard error is obtained from the residuals and the model’s degrees of freedom.
For the simple regression model, the residual standard error is \(RSE =\) 11.18, whereas for the multiple regression model it is \(RSE =\) 8.96. The lower RSE in the multiple regression model indicates that its fitted values are, on average, closer to the observed unit_price values. This suggests that including the additional predictors improves the model’s fit to the data.
Because RSE is expressed in the same units as the response variable, its interpretation is always contextual. A value is meaningful only relative to the scale of the response and the purpose of the analysis.
R-squared and Adjusted R-squared
The coefficient of determination, \(R^2\), measures the proportion of variability in the response variable that is explained by the regression model. It summarizes how well the fitted model captures the overall variation in the data.
Formally, \(R^2\) is defined as \[ R^2 = 1 - \frac{SSE}{SST}, \] where \(SSE\) is the sum of squared errors defined in Equation 10.1 and \(SST\) is the total sum of squares, representing the total variation in the response. The value of \(R^2\) ranges between 0 and 1. A value of 1 means that the model explains all observed variation, whereas a value of 0 means that it explains none.
For the simple regression model predicting unit_price from stores_number, the value of \(R^2\) is
round(summary(simple_reg)$r.squared, 3)
[1] 0.326This means that approximately 32.6% of the variation in unit_price is explained by the regression model using stores_number as the predictor. In simple linear regression, \(R^2\) is directly related to the Pearson correlation coefficient introduced in Section 5.13, since \[
R^2 = r^2,
\] where \(r\) is the correlation between the predictor and the response. In the house dataset, we can verify this directly:
round(cor(house$stores_number, house$unit_price)^2, 3)
[1] 0.326This gives the same value as the reported \(R^2\), reinforcing that in simple linear regression, \(R^2\) reflects the strength of the linear association between the predictor and the response.
However, \(R^2\) has an important limitation: it never decreases when predictors are added, even if the additional variables contribute little useful information. For this reason, \(R^2\) alone can be misleading when comparing models of different complexity. Adjusted \(R^2\) addresses this limitation by accounting for the number of predictors in the model.
Adjusted \(R^2\) is defined as \[ \text{Adjusted } R^2 = 1 - \left(1 - R^2\right)\times\frac{n - 1}{n - m - 1}, \] where \(n\) is the number of observations and \(m\) is the number of predictors. Unlike \(R^2\), adjusted \(R^2\) may increase or decrease when a new predictor is added, depending on whether the improvement in fit is large enough to justify the added complexity.
For the simple regression model, adjusted \(R^2\) is
round(summary(simple_reg)$adj.r.squared, 3)
[1] 0.324which is close to the corresponding \(R^2\) value because only one predictor is included.
The comparison becomes more informative when we look at the simple and multiple regression models together. For the simple regression model, \(R^2 =\) 32.6%, whereas for the multiple regression model it increases to \(R^2 =\) 57.1%. Similarly, adjusted \(R^2\) rises from 32.4% in the simple regression model to 56.6% in the multiple regression model.
These increases indicate that the additional predictors in the multiple regression model help explain more of the variation in unit_price than stores_number alone. At the same time, neither \(R^2\) nor adjusted \(R^2\) guarantees that a model is appropriate or that it will predict well on unseen data. Both measures should therefore be interpreted alongside diagnostics and, when prediction is the goal, alongside out-of-sample evaluation.
Interpreting Model Quality
Assessing the quality of a regression model requires balancing several complementary measures rather than relying on a single statistic. In general, a better-fitting model has a lower residual standard error, indicating that the fitted values are closer to the observed values, together with relatively high values of \(R^2\) and adjusted \(R^2\), suggesting that the model explains a substantial proportion of the variability in the response without unnecessary complexity.
Taken together, the comparisons in this section suggest that the multiple regression model provides a better fit to the house data than the simple regression model. Its lower RSE and higher values of \(R^2\) and adjusted \(R^2\) indicate that incorporating the additional predictors improves the model beyond using stores_number alone.
At the same time, these summaries should not be interpreted in isolation. A model with strong numerical fit may still violate important assumptions or include predictors that add little practical value. Measures of model quality should therefore be considered alongside residual diagnostics, graphical checks, subject-matter interpretation, and, when relevant, predictive evaluation on new data.
Practice: Fit a reduced multiple regression model by removing the predictor
longitudefromfull_model. How do the RSE, \(R^2\), and adjusted \(R^2\) change? What do these changes suggest about the contribution of the omitted predictor?
This comparison naturally leads to a broader modeling question: should all available predictors be retained, or is there a smaller subset that balances simplicity and performance? We address this issue in Section 10.5, where we introduce stepwise regression and related model selection strategies.
10.4 Hypothesis Testing in Regression Models
Measures such as RSE, \(R^2\), and adjusted \(R^2\) help us assess how well a regression model fits the observed data, but they do not tell us whether individual regression coefficients are statistically distinguishable from zero. To answer that question, we turn to hypothesis testing.
We begin with the simplest setting: simple linear regression. In this case, inference focuses on the slope coefficient. Specifically, we ask whether the estimated slope \(b_1\) provides evidence of a linear association in the population, where the corresponding population parameter is denoted by \(\beta_1\). The population regression model is \[ y = \beta_0 + \beta_1 x + \epsilon, \] where \(\beta_0\) is the population intercept, \(\beta_1\) is the population slope, and \(\epsilon\) represents random variation not explained by the model.
The key inferential question is whether \(\beta_1\) differs from zero. If \(\beta_1 = 0\), then the predictor \(x\) has no linear association with the response in the population, and the model simplifies to \[ y = \beta_0 + \epsilon. \]
We formalize this question through the hypotheses \[ \begin{cases} H_0: \beta_1 = 0 & \text{(no linear relationship between $x$ and $y$)}, \\ H_a: \beta_1 \neq 0 & \text{(a linear relationship exists)}. \end{cases} \]
To test these hypotheses, we compute the t-statistic \[ t = \frac{b_1}{SE(b_1)}, \] where \(SE(b_1)\) is the standard error of the slope estimate. Under the null hypothesis, this statistic follows a t-distribution with \(n - 2\) degrees of freedom, reflecting the estimation of two parameters in simple linear regression. The associated p-value measures how unusual it would be to observe a slope estimate as extreme as \(b_1\) if \(H_0\) were true.
We now return to the summary output of the simple regression model introduced in Section 10.1, focusing on the inferential quantities associated with the slope coefficient. From this output, the estimated slope is \(b_1 =\) 2.64, with a corresponding t-statistic of 14.12 and a p-value of <2e-16. Because this p-value is very small, we reject the null hypothesis.
This result provides strong statistical evidence of a linear association between stores_number and unit_price. Interpreted in context, the estimated slope indicates that one additional nearby store is associated with an average increase of approximately 2.64 in unit price.
Practice: In simple linear regression with one predictor, testing whether the slope equals zero is closely related to testing whether the correlation between the predictor and response equals zero. Using the
housedataset, perform a correlation test forstores_numberandunit_priceas in Section 5.13, and compare the result to the hypothesis test for the slope in the regression model. What do you observe about the test conclusion and the associated p-value?
The same inferential logic extends to the multiple regression model introduced in Section 10.2. In that setting, each coefficient is tested while holding the other predictors constant. For example, in the model full_model, the hypothesis test for the coefficient of stores_number asks whether the number of nearby stores remains associated with unit_price after adjusting for the other predictors in the model.
In multiple regression, each reported t-statistic and p-value must therefore be interpreted coefficient by coefficient, conditional on the other predictors in the model. This is one of the main inferential advantages of multiple regression: it allows us to assess whether a predictor contributes information beyond what is already explained by the others. It also means that a predictor that appears important in a simple regression model may become weaker, or no longer statistically significant, once additional variables are included, especially when predictors share overlapping information.
It is important to distinguish statistical significance from practical importance. A coefficient may be statistically significant but too small to matter in practice, especially in a large dataset. It is equally important to remember that statistical significance does not imply causation. Hypothesis testing tells us whether a coefficient is statistically distinguishable from zero under the model, not whether the relationship is causal or whether the model will necessarily predict well on new data.
Hypothesis testing therefore adds an inferential perspective to regression analysis, but it is only one part of model building. In practice, we must still balance interpretability, explanatory value, predictive usefulness, and model complexity. We turn to this issue next in the section on stepwise regression for predictor selection.
10.5 Stepwise Regression for Predictor Selection
An important practical question in regression modeling is deciding which predictors to include. Including too few variables may leave important relationships unexplained, whereas including too many can reduce interpretability and lead to unnecessary complexity. Predictor selection therefore aims to balance explanatory value with simplicity.
Stepwise regression is one commonly used approach to this problem. It is an iterative procedure that adds or removes predictors one at a time according to a model selection criterion. In this way, it provides a systematic way to compare competing predictor sets and search for a model that is both interpretable and effective.
This idea connects naturally to earlier parts of the data science workflow. Exploratory analysis helps identify potentially useful predictors, while regression modeling allows us to assess how those predictors contribute once considered together. Stepwise regression builds on these earlier steps by automating part of the model selection process.
How AIC Guides Model Selection
When comparing competing regression models, we need a principled way to decide whether a simpler model is preferable to a more complex one. Model selection criteria address this problem by balancing goodness of fit against model complexity, so that additional predictors are retained only when they improve the model enough to justify their inclusion.
One widely used criterion is the Akaike Information Criterion (AIC). AIC combines a measure of model fit with a penalty for complexity, with lower values indicating a better trade-off. For linear regression, AIC can be expressed, up to an additive constant, as \[ AIC = 2m + n \log\left(\frac{SSE}{n}\right), \] where \(m\) denotes the number of estimated parameters in the model, \(n\) is the number of observations, and \(SSE\) is the sum of squared errors introduced in Equation 10.1.
Unlike \(R^2\), which never decreases when predictors are added, AIC explicitly penalizes model complexity. As a result, a predictor is retained only if the improvement in fit is large enough to justify the added complexity. AIC is therefore a relative measure: it is meaningful only when comparing models fitted to the same dataset and response variable, and among the candidate models, the one with the smaller AIC is preferred.
A related criterion is the Bayesian Information Criterion (BIC), which penalizes complexity more strongly and therefore tends to favor simpler models. In this chapter, however, we focus on AIC because it is the default criterion used by the step() function in R.
Stepwise Regression in Practice: Using step() in R
We now apply stepwise regression to the house dataset. In R, the step() function automates predictor selection by iteratively adding or removing variables to improve the AIC value. Its general syntax is
Here, object is a fitted model, and the direction argument specifies the search strategy. Forward selection starts from a smaller model and adds predictors, backward elimination begins with a fuller model and removes predictors, and "both" allows movement in either direction.
For the house data, we begin with the full multiple regression model introduced earlier in Section 10.2. This model, stored as full_model, includes all available predictors of unit_price. As already noted, some coefficient estimates may have relatively large p-values. That does not necessarily mean that those predictors are unimportant. When predictors contain overlapping information, their individual contributions can be difficult to separate clearly within a single model. This is closely related to multicollinearity, which can inflate standard errors and complicate interpretation even when the model as a whole fits the data well.
This motivates the use of automated model selection techniques. We apply stepwise regression using AIC as the selection criterion and allowing both forward and backward moves:
stepwise_model <- step(full_model, direction = "both")
Start: AIC=1822.01
unit_price ~ house_age + distance_to_MRT + stores_number + latitude +
longitude
Df Sum of Sq RSS AIC
- longitude 1 2.0 32792 1820.0
<none> 32790 1822.0
- latitude 1 2248.8 35038 1847.5
- distance_to_MRT 1 2786.3 35576 1853.8
- stores_number 1 3004.2 35794 1856.3
- house_age 1 3821.9 36611 1865.7
Step: AIC=1820.03
unit_price ~ house_age + distance_to_MRT + stores_number + latitude
Df Sum of Sq RSS AIC
<none> 32792 1820.0
+ longitude 1 2.0 32790 1822.0
- latitude 1 2299.3 35091 1846.1
- stores_number 1 3023.6 35815 1854.5
- house_age 1 3820.2 36612 1863.7
- distance_to_MRT 1 5755.8 38547 1885.0The algorithm evaluates alternative models by adding or removing predictors, retaining only those changes that reduce the AIC. This process continues until no further improvement is possible. Across the iterations, the AIC decreases from 1822.01 for the full model to 1820.03 for the final selected model, indicating a slightly more favorable balance between fit and complexity.
To see which predictors remain in the final model, we inspect its formula:
formula(stepwise_model)
unit_price ~ house_age + distance_to_MRT + stores_number + latitudeThe stepwise procedure removes only one predictor, longitude. This suggests that, after accounting for the other variables in the model, longitude does not contribute enough additional information to be retained under the AIC criterion. All other predictors from the full model remain in the final specification.
Compared with the full model, the stepwise model is only slightly simpler. Its residual standard error changes from 8.96 to 8.95, while adjusted \(R^2\) changes from 56.6% to 56.7%. These values show that removing longitude has very little effect on the overall fit of the model.
Stepwise regression therefore provides a practical way to compare competing predictor sets, especially when several predictors may contain overlapping information. At the same time, it remains a heuristic approach and should be complemented with subject-matter knowledge, diagnostic checks, and validation whenever possible.
Practice: Apply stepwise regression using
"forward"and"backward"selection instead of"both". Do all three approaches lead to the same final model? How do their AIC values compare?
Considerations for Stepwise Regression
Stepwise regression provides a structured and computationally efficient approach to predictor selection. By iteratively adding or removing variables according to a model selection criterion, it offers a practical way to compare competing models without evaluating every possible predictor combination. When used carefully, it can produce simpler and more interpretable models.
At the same time, stepwise regression has important limitations. Because predictors are evaluated sequentially rather than jointly, the procedure may miss combinations of variables or interaction effects that become useful only when considered together. The selected model can also be sensitive to sampling variability, so small changes in the data may lead to different results. When many predictors are available relative to the sample size, stepwise regression may favor models that capture random noise rather than stable patterns. Multicollinearity can further complicate interpretation by inflating standard errors and obscuring individual contributions.
In settings with many predictors or more complex dependence structures, regularization methods such as LASSO and ridge regression are often attractive alternatives. These approaches shrink coefficient estimates through explicit penalty terms and can produce more stable models, especially when predictors are numerous or highly correlated. A broader introduction to these methods is provided in An Introduction to Statistical Learning with Applications in R (Gareth et al. 2013).
Ultimately, predictor selection should be guided by a combination of statistical criteria, subject-matter knowledge, and validation on representative data. Stepwise regression is therefore best viewed not as a definitive solution, but as a useful exploratory tool that can support model building when applied with care.
10.6 Modeling Non-Linear Relationships
Not all relationships between predictors and a response variable are well described by straight lines. In many applications, the effect of a predictor changes across its range, so that the relationship is curved rather than linear. When this happens, a standard linear regression model may miss important structure in the data and produce systematic errors.
Earlier in this chapter, we used stepwise regression (Section 10.5) to decide which predictors to retain in the model. That approach helps refine model specification, but it does not address the form of the relationship between a predictor and the response. If the underlying pattern is curved, simply adding or removing predictors will not solve the problem.
To handle this situation while preserving the familiar regression framework, we turn to polynomial regression. This approach extends linear regression by allowing transformed versions of a predictor, such as squared terms, to enter the model. In this way, it can capture curvature while retaining the same basic tools for estimation, interpretation, and prediction.
When a Straight Line Is Not Enough
A useful way to see why non-linear terms may be needed is to examine the relationship between house_age and unit_price in the house dataset. Figure Figure 10.5 shows a scatter plot of these two variables. The dashed gray line represents a simple linear regression fit, while the dark blue curve represents a quadratic fit.
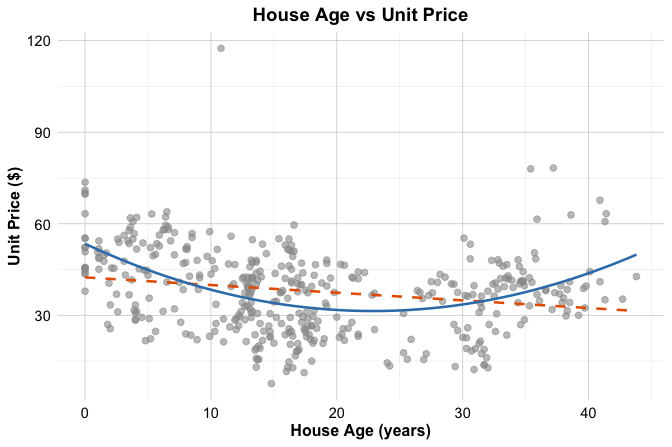
unit_price versus house_age in the house dataset, with a fitted linear regression line shown as a dashed gray line and a fitted quadratic curve shown in dark blue.
The figure suggests that the relationship is not fully captured by a straight line. The linear fit follows the overall direction of the data, but it does not reflect the visible curvature particularly well. In contrast, the quadratic curve follows the pattern more closely, suggesting that the effect of house_age on unit_price is not constant across the full range of the predictor.
A quadratic regression model has the form \[ \widehat{\text{unit\_price}} = b_0 + b_1 \times \text{house\_age} + b_2 \times \text{house\_age}^2. \]
By including both house_age and its squared term, the fitted relationship is allowed to bend rather than remain straight. Although the relationship between the predictor and the response is now nonlinear, the model is still linear in the coefficients \(b_0\), \(b_1\), and \(b_2\). For that reason, it is still estimated using ordinary least squares.
This plot is intended to build intuition by isolating the relationship between house_age and unit_price. In the next section, we return to the multivariable regression setting and examine whether adding a quadratic term for house_age improves the earlier model selected from the house data.
10.7 Polynomial Regression in Practice
We now return to the house dataset and examine how polynomial regression can be used in a multivariable setting. In the previous section, we used the relationship between house_age and unit_price to build intuition for why a straight-line fit may be insufficient. We now extend that idea to the regression model selected earlier by the stepwise procedure.
The stepwise model retained the predictors house_age, distance_to_MRT, stores_number, and latitude, but it treated the effect of house_age as linear. Because the earlier scatter plot suggested curvature in the relationship between house_age and unit_price, it is natural to ask whether the model improves when we allow this relationship to bend.
To do so, we add a quadratic term for house_age while retaining the other predictors from the stepwise model. The resulting polynomial regression model is \[\begin{equation}
\begin{split}
\widehat{\text{unit\_price}} &=
b_0 + b_1 \times \text{house\_age} +
b_2 \times \text{house\_age}^2 +
b_3 \times \text{distance\_to\_MRT} + \\
&\quad b_4 \times \text{stores\_number} +
b_5 \times \text{latitude}.
\end{split}
\end{equation}\]
This model remains linear in the coefficients, even though the relationship between house_age and unit_price is no longer restricted to a straight line. We can therefore fit it using the same lm() function as before.
poly_reg_house <- lm(
unit_price ~ house_age + I(house_age^2) + distance_to_MRT +
stores_number + latitude,
data = house
)
summary(poly_reg_house)
Call:
lm(formula = unit_price ~ house_age + I(house_age^2) + distance_to_MRT +
stores_number + latitude, data = house)
Residuals:
Min 1Q Median 3Q Max
-31.573 -5.160 -0.753 4.309 77.758
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -6.225e+03 1.070e+03 -5.818 1.20e-08 ***
house_age -1.102e+00 1.446e-01 -7.616 1.84e-13 ***
I(house_age^2) 2.090e-02 3.507e-03 5.961 5.44e-09 ***
distance_to_MRT -3.530e-03 4.854e-04 -7.272 1.82e-12 ***
stores_number 1.086e+00 1.826e-01 5.945 5.93e-09 ***
latitude 2.512e+02 4.284e+01 5.863 9.38e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 8.598 on 408 degrees of freedom
Multiple R-squared: 0.6055, Adjusted R-squared: 0.6007
F-statistic: 125.2 on 5 and 408 DF, p-value: < 2.2e-16In the summary output, we see two coefficients related to house_age: one for house_age and one for I(house_age^2). This is because the model includes both the linear term and the squared term. Together, these two coefficients determine the curved relationship between house_age and unit_price. As a result, the effect of house_age can no longer be interpreted using a single slope alone.
We now compare this polynomial model with the earlier stepwise linear model. If the quadratic term captures meaningful curvature, we would expect the polynomial model to improve the fit. For the stepwise linear model, the residual standard error is 8.95 and the adjusted \(R^2\) is 0.567. For the polynomial model, the residual standard error decreases to 8.6, while the adjusted \(R^2\) increases to 0.601. The polynomial model therefore has a lower residual standard error and a higher adjusted \(R^2\). This suggests that allowing curvature in house_age improves the model beyond the purely linear specification. In other words, the quadratic term appears to capture structure that the stepwise model leaves unexplained.
Polynomial regression therefore provides a useful extension of multiple regression when one predictor appears to have a nonlinear relationship with the response. At the same time, polynomial terms should be added thoughtfully and only when they are supported by the data and improve the model in a meaningful way. In the next section, we examine whether this refinement is also supported by the diagnostic plots.
Practice: Fit a cubic extension of the model by replacing
I(house_age^2)with bothI(house_age^2)andI(house_age^3). Compare the cubic and quadratic models using the residual standard error, adjusted \(R^2\), and the diagnostic plots. Does the added cubic term appear to improve the model enough to justify the extra complexity?
10.8 Diagnosing Common Problems in Regression Models
A regression model may appear to perform well according to measures such as \(R^2\), adjusted \(R^2\), or the residual standard error, yet still suffer from important weaknesses. Before we rely on a fitted model for interpretation or prediction, we therefore need to examine whether it shows signs of systematic problems. Diagnostic analysis helps us do this by revealing patterns in the residuals, highlighting unusual observations, and showing whether the fitted model captures the structure of the data adequately.
Linear regression is built on several familiar assumptions, including linearity, constant variance, approximate normality of residuals, and independence of observations. In practice, however, it is often more useful to approach diagnostics through the concrete problems that arise when these assumptions are not well satisfied. Rather than asking only whether an assumption holds in the abstract, we ask three practical questions: What can go wrong, how can we recognize it, and what might we do in response?
Even when a polynomial model improves numerical fit, it is still important to check whether the fitted model behaves reasonably. To illustrate this process, we return to the house dataset and focus on the polynomial regression model introduced earlier. In that model, unit_price is explained using house_age, its squared term, distance_to_MRT, stores_number, and latitude. The standard diagnostic plots for this model are shown in Figure 10.6. Here we use the autoplot() function from ggfortify because it provides a clean and convenient display of the standard regression diagnostics, although the same plots can also be obtained using the base plot() function in R. The lower-right panel additionally includes Cook’s distance contours, which help us identify cases that may have a relatively strong influence on the fitted model.

house dataset.
These four plots provide complementary perspectives on model adequacy. The Residuals vs Fitted plot (upper-left) helps us assess linearity and constant variance, the Normal Q-Q plot (upper-right) helps us assess whether the residuals are approximately normal, the Scale-Location plot (lower-left) provides another view of residual spread, and the Residuals vs Leverage plot (lower-right) helps us identify observations that may be influential. Taken together, these plots do not provide automatic yes-or-no answers, but they help us judge whether the fitted model behaves reasonably or whether some aspects require closer attention. In the following subsections, we examine these diagnostic perspectives in more detail.
One important issue is not well captured by the four standard diagnostic plots: dependence among observations. Standard linear regression assumes that each observation contributes independent information, but this may be questionable in datasets with temporal, spatial, clustered, or repeated-measurement structure. When dependence is present, the fitted regression function may still appear reasonable, but the standard errors and inferential conclusions can become unreliable. For this reason, regression diagnostics require not only plot-based checks, but also careful attention to how the data were collected and structured.
In this case, the plots do not suggest any severe violation of the main regression assumptions, although observation 271 stands out and deserves closer inspection. The Cook’s distance contours in the Residuals vs Leverage plot help us assess whether this case may also have an important influence on the fitted model.
Non-Linearity of the Response-Predictor Relationship
One of the most common problems in regression analysis is non-linearity. A linear regression model assumes that the response changes linearly with the predictors included in the model, given the structure specified by the model. When this assumption is not appropriate, the fitted model may systematically underpredict in some regions of the data and overpredict in others.
A useful tool for detecting this problem is the Residuals vs Fitted plot. If the assumed functional form is adequate, the residuals should appear randomly scattered around zero with no clear structure. Curved patterns or other systematic departures suggest that the model is missing important non-linear structure.
To illustrate this, Figure 10.7 compares the Residuals vs Fitted plots for two models fitted to the house dataset: the earlier stepwise linear model stepwise_model and the polynomial regression model poly_reg_house. This comparison is especially useful because it shows not only what non-linearity looks like in practice, but also how a model can be improved once that pattern is detected. The stepwise model includes house_age, distance_to_MRT, stores_number, and latitude, but assumes a linear effect of house_age. The polynomial model extends this specification by adding the squared term \(house\_age^2\).
In the stepwise linear model (left panel), the residuals show a noticeable curved pattern, suggesting that the model does not fully capture the relationship between house_age and unit_price. In the polynomial model (right panel), this pattern is less pronounced, and the residuals appear more randomly scattered around zero. This suggests that allowing curvature in house_age provides a better representation of the underlying relationship.
autoplot(stepwise_model, which = 1, ncol = 1) +
ggtitle("Stepwise linear model")
autoplot(poly_reg_house, which = 1, ncol = 1) +
ggtitle("Polynomial model")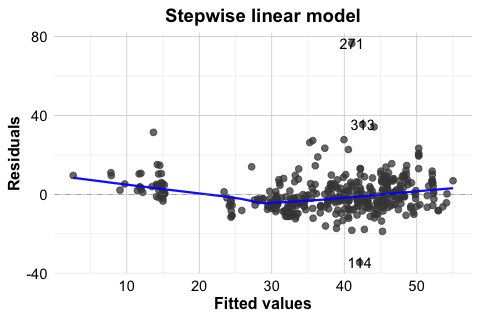
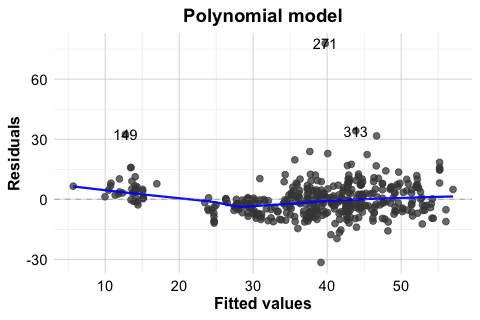
house dataset.
This comparison shows that diagnostic plots are useful not only for identifying problems but also for guiding model improvement. When non-linearity is present, possible responses include transforming a predictor, adding polynomial terms, or adopting a more flexible modeling approach. In this example, the residual plots support the earlier decision to include a quadratic term for house_age.
Non-Constant Variance
A second common problem in regression analysis is non-constant variance, also known as heteroscedasticity. Linear regression assumes that the variability of the residuals remains roughly stable across the range of fitted values. When this assumption does not hold, the residual spread changes systematically as the fitted values increase or decrease. This can affect standard errors, confidence intervals, and hypothesis tests, even when the fitted mean trend appears reasonable.
Two useful diagnostic tools for this issue are the Residuals vs Fitted plot and the Scale-Location plot. If the constant-variance assumption is reasonable, the residuals should show a fairly even spread across the fitted values. A funnel shape, in which the spread widens or narrows as the fitted values change, suggests heteroscedasticity.
In the house example, the Residuals vs Fitted and Scale-Location plots do not suggest severe heteroscedasticity. Still, it is useful to see this problem in a clearer setting. For that reason, Figure 10.8 presents a simulated example in which the variance increases with the level of the response. In the left panel, the residuals from a regression model fitted to the original response y show a pronounced funnel shape. In the right panel, the model is refitted using log(y) as the response. The residual spread is much more even, illustrating how a transformation can sometimes stabilize variance.
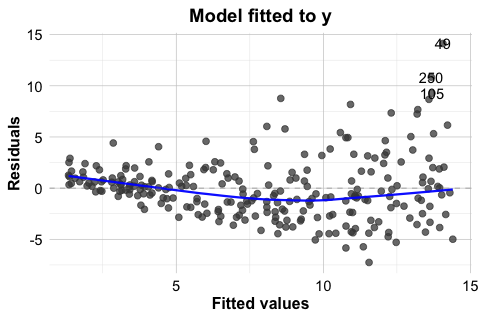
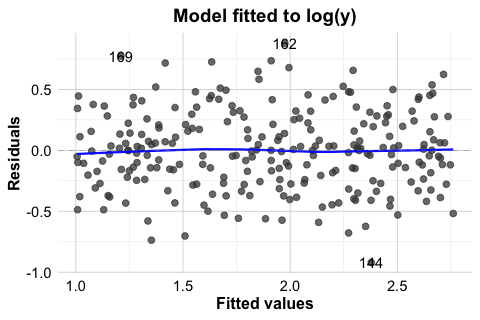
This example shows that heteroscedasticity is often easier to recognize visually than through a single summary statistic. It also illustrates one common response: transforming the response variable. In practice, however, transformations should be guided by the scientific context and by the scale on which interpretation remains meaningful.
The Scale-Location plot in Figure 10.6 provides another useful view of this issue by showing how the spread of standardized residuals changes across the fitted values. Taken together, these plots help us judge whether the constant-variance assumption is reasonably satisfied or whether the model may need adjustment.
Non-Normal Residuals
Another diagnostic concern is whether the residuals are approximately normally distributed. This issue is less important for estimating the regression function itself than for inference, since the reliability of confidence intervals and hypothesis tests depends in part on the residual distribution, especially when the sample size is small.
A standard tool for assessing this assumption is the Normal Q-Q plot. If the residuals are approximately normal, the points should lie close to the diagonal reference line. Systematic departures from that line, particularly in the tails, may suggest skewness, heavy tails, or other departures from normality.
As with non-constant variance, it is useful to compare the fitted house model with a clearer simulated example. In the house example, the Q-Q plot for the polynomial regression model does not suggest a serious violation of normality. Still, it is useful to compare this with a case where the assumption is clearly not satisfied. For this reason, Figure 10.9 shows two Q-Q plots. The left panel displays the residuals from poly_reg_house, which follow the reference line reasonably closely. The right panel shows a simulated example with clearly non-normal residuals. In that case, the pronounced deviation from the line indicates that the normality assumption is not appropriate.
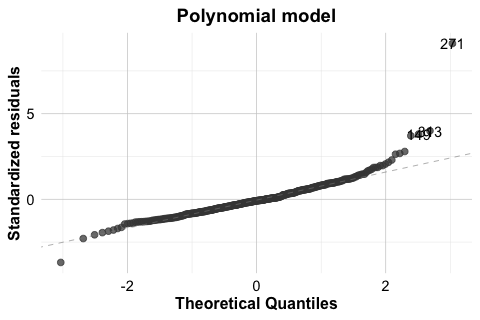
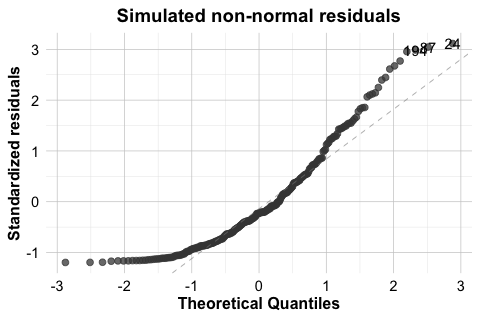
house dataset and for a simulated model with non-normal residuals.
When residuals depart substantially from normality, inferential results should be interpreted more cautiously. Possible responses include transforming the response variable, reconsidering the model form, or using more robust methods when appropriate. The goal is not to force perfect normality, but to judge whether the departure is mild enough to tolerate or substantial enough to affect the conclusions.
Influential Observations
A regression model can also be affected by a small number of influential observations. These are cases that have the potential to exert disproportionate influence on the fitted model. In practice, influence is often greatest when a case combines an unusual position in the predictor space with a relatively large residual.
The Residuals vs Leverage plot in the lower-right panel of Figure 10.6 helps identify such cases. Observations with high leverage lie in unusual regions of the predictor space. If such observations also have large residuals, they may strongly affect the estimated coefficients and the fitted regression line. The Cook’s distance contours in this plot provide additional guidance by indicating which cases may have relatively large influence on the overall fit.
In the house example, observation 271 stands out because it has a relatively large residual. This makes it a useful case for closer inspection. However, a large residual alone does not automatically imply strong influence. To be influential, a case typically must also have substantial leverage. The diagnostic plot suggests that no single observation dominates the fitted model to an extreme degree, although some deserve additional attention. This distinction matters because unusual observations are not all equally important for the fitted model.
When potentially influential observations are identified, they should not be removed automatically. Instead, we should first examine whether they reflect data entry errors, measurement problems, or unusual but valid cases. In some situations, an influential observation reveals an important feature of the data rather than a defect. In others, it may suggest that the model form should be reconsidered.
Practice: In the Residuals vs Leverage plot, locate observation 271. Does it stand out mainly because of its residual size, its leverage, or both?
Diagnostic analysis is not a separate step performed only after a model has been fitted. It is part of the modeling process itself. In practice, we rarely expect a model to satisfy every assumption perfectly. The more important question is whether any violations are mild enough to tolerate or serious enough to affect interpretation, inference, or prediction. For this reason, regression diagnostics help us move beyond mechanical model fitting toward a more careful and reliable analysis.
10.9 Case Study: Predicting Hourly Bike Rental Demand
How can we predict how many bikes will be rented in the next hour? For a bike-sharing system, this is an important practical question. Accurate short-term predictions can help operators distribute bicycles more efficiently across stations, anticipate peak demand, and improve service availability throughout the day.
In this case study, we use regression to model hourly bike rental demand using weather conditions and time-related information. The analysis is based on a real-world bike-sharing dataset from Seoul, available in the liver package. Because the response variable is numerical, regression provides a natural starting point. At the same time, the dataset presents several realistic challenges: demand changes sharply across hours of the day, differs between weekdays and weekends, varies across seasons, and does not respond linearly to all weather variables. This makes the dataset a useful setting for showing how regression models can be strengthened through careful feature construction, response transformation, and model specification.
We follow the Data Science Workflow introduced in Chapter 2 and illustrated in Figure 2.1. The analysis also builds on the exploratory data analysis strategies from Chapter 4 and the data setup principles from Chapter 6. By moving step by step from understanding the problem and the data to model fitting, diagnostic checking, evaluation, and interpretation, this case study shows how regression can support informed prediction of hourly bike rental demand.
In this setting, hourly demand is shaped by both environmental conditions and regular daily patterns. For example, demand may increase during commuting hours, decline late at night, and respond differently under mild, rainy, or very cold weather conditions. These patterns suggest that effective prediction will require us to account for both time-related structure and weather-related effects.
To carry out this case study, we use several R packages. The liver package provides the dataset, dplyr is used for data preparation, ggplot2 for visualization, lubridate for working with dates, and ggfortify for regression diagnostics.
Data Understanding, Preparation, and Exploration
We begin by loading the dataset and examining its structure. The bike_demand dataset, available in the liver package, contains hourly records of bike rental demand together with weather and calendar-related information. Our response variable is bike_count, which records the number of rented bikes in each hour.
data(bike_demand)
str(bike_demand)
'data.frame': 8760 obs. of 14 variables:
$ date : chr "01/12/2017" "01/12/2017" "01/12/2017" "01/12/2017" ...
$ hour : int 0 1 2 3 4 5 6 7 8 9 ...
$ temperature : num -5.2 -5.5 -6 -6.2 -6 -6.4 -6.6 -7.4 -7.6 -6.5 ...
$ humidity : int 37 38 39 40 36 37 35 38 37 27 ...
$ wind_speed : num 2.2 0.8 1 0.9 2.3 1.5 1.3 0.9 1.1 0.5 ...
$ visibility : int 2000 2000 2000 2000 2000 2000 2000 2000 2000 1928 ...
$ dew_point_temperature: num -17.6 -17.6 -17.7 -17.6 -18.6 -18.7 -19.5 -19.3 -19.8 -22.4 ...
$ solar_radiation : num 0 0 0 0 0 0 0 0 0.01 0.23 ...
$ rainfall : num 0 0 0 0 0 0 0 0 0 0 ...
$ snowfall : num 0 0 0 0 0 0 0 0 0 0 ...
$ season : Factor w/ 4 levels "autumn","spring",..: 4 4 4 4 4 4 4 4 4 4 ...
$ holiday : Factor w/ 2 levels "holiday","no holiday": 2 2 2 2 2 2 2 2 2 2 ...
$ functioning_day : Factor w/ 2 levels "no","yes": 2 2 2 2 2 2 2 2 2 2 ...
$ bike_count : int 254 204 173 107 78 100 181 460 930 490 ...The dataset includes weather-related variables such as temperature, humidity, wind_speed, visibility, dew_point_temperature, solar_radiation, rainfall, and snowfall. It also contains time-related variables such as date, hour, season, holiday, and functioning_day. Together, these variables suggest that bike demand is shaped by both environmental conditions and regular daily or seasonal patterns.
Before fitting regression models, we prepare the data for analysis. Since the rental system is unavailable on non-functioning days, we restrict the analysis to observations where functioning_day == "yes". This allows us to focus on modeling variation in hourly demand when the bike-sharing system is actually operating.
To begin the preparation, we create a new object called bike_data so that the original dataset remains unchanged. We then convert the date variable to a proper date format and derive two calendar-based features from it: weekday and month. The weekday variable helps distinguish between weekdays and weekends, while month is useful during exploratory analysis for identifying broader seasonal patterns.
bike_data <- bike_demand
bike_data$date <- as.Date(bike_data$date, format = "%d/%m/%Y")
bike_data$weekday <- factor(
lubridate::wday(bike_data$date, label = TRUE, abbr = TRUE, week_start = 1),
levels = c("Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun")
)
bike_data$month <- factor(
lubridate::month(bike_data$date, label = TRUE, abbr = TRUE),
levels = month.abb
)Next, we keep only the observations recorded during functioning periods.
bike_data <- dplyr::filter(bike_data, functioning_day == "yes")We then sort the observations chronologically by date and hour. This is important because later we will divide the data into training and test sets based on time, so the rows must be ordered from earlier to later observations.
bike_data <- dplyr::arrange(bike_data, date, hour)Finally, we convert hour to a factor. Bike demand is unlikely to change in a simple linear way over the course of the day. For example, demand may increase during commuting hours and decrease late at night. Treating hour as a categorical variable allows the regression model to estimate a separate effect for each hour.
bike_data$hour <- factor(bike_data$hour, levels = 0:23)We now examine the distribution of the response variable. The distribution of bike_count is right-skewed, with many moderate values and a smaller number of much larger counts. Such a pattern suggests that modeling the response directly may lead to non-constant variance and a less stable regression fit. To assess whether a simple transformation improves the shape of the distribution, we compare bike_count with its square-root transformation.
ggplot(bike_data, aes(x = bike_count)) +
geom_histogram(bins = 30) +
labs(x = "Hourly bike rentals", y = "Frequency")
ggplot(bike_data, aes(x = sqrt(bike_count))) +
geom_histogram(bins = 30) +
labs(x = "Square-root transformed rentals", y = "Frequency")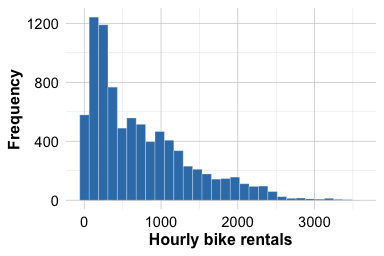
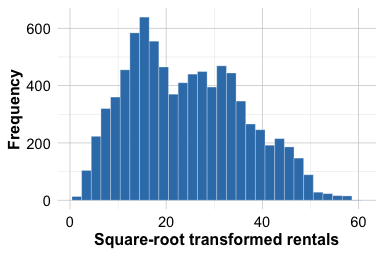
Figure Figure 10.10 shows that bike_count is clearly right-skewed, with many relatively small or moderate values and a smaller number of much larger counts. The distribution is not close to symmetric. In contrast, the square-root transformation reduces the skewness and compresses the range of large values, so that the transformed response appears more symmetric and more nearly bell-shaped around its center. This provides a practical reason to model bike demand on the transformed scale. We therefore create a new response variable, sqrt_bike_count, which will be used in the regression models that follow.
Practice: Try an alternative transformation of
bike_count, such aslog(bike_count + 1), and compare the resulting distribution with the histograms in Figure Figure 10.10. Does this alternative appear more suitable than the square-root transformation for this dataset?
bike_data$sqrt_bike_count <- sqrt(bike_data$bike_count)To better understand the daily pattern of bike use, we next examine how average demand changes across the hours of the day.
ggplot(bike_data, aes(x = hour, y = bike_count, group = 1)) +
stat_summary(fun = mean, geom = "line", linewidth = 1) +
stat_summary(fun = mean, geom = "point", size = 2) +
labs(x = "Hour of day", y = "Average bike rentals")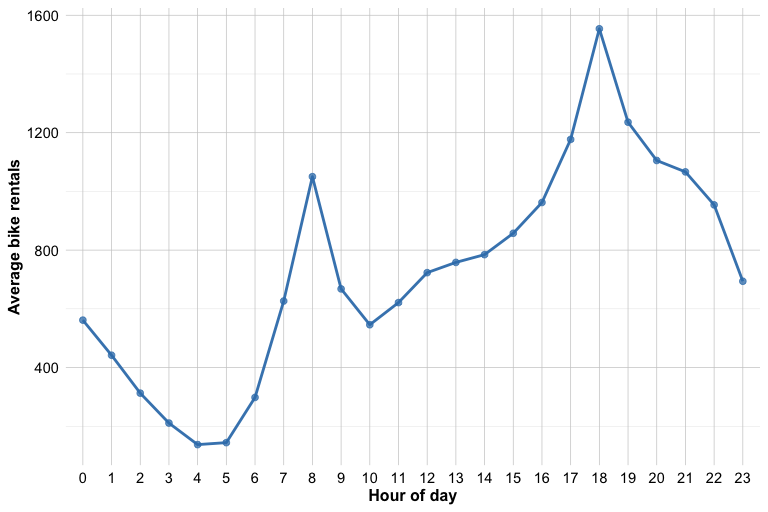
Figure Figure 10.11 shows that bike demand does not vary linearly over the course of the day. Instead, it follows a clear daily pattern, with two pronounced peaks around 08:00 and 18:00. These peaks may reflect commuting behavior, as bike use often increases at the beginning and end of the working day. Demand is much lower during late-night and early-morning periods, then rises again as daily activity begins. This pattern suggests that the effect of hour is not well represented by a single straight-line trend. For this reason, we treat hour as a factor rather than as a numeric predictor, allowing the regression model to estimate a separate effect for each hour of the day.
Practice: Look at Figure Figure 10.11. Which hours appear to have the highest average demand, and why does this pattern suggest that
hourshould be treated as a factor rather than as a numeric predictor?
Although we created both weekday and month, they will not play the same role later in the analysis. The weekday variable will be used in the final regression models because differences between weekdays and weekends are directly relevant for prediction. The month variable is useful during exploratory analysis, but we do not include it in the final regression models. Because the data will later be split chronologically, the final portion of the year forms the test set, and using month as a factor could introduce levels in the test data that are not represented in the training data.
Data Setup for Modeling
Because the observations are ordered over time, we evaluate the model using future observations rather than a random sample from the full dataset. In this setting, a random train-test split would mix earlier and later time points, which would not reflect the practical goal of predicting future bike demand from past data. Instead, we use the first 80% of the observations as the training set and the remaining 20% as the test set.
This split is more realistic for a time-ordered dataset because it respects the chronological structure of the observations. It also reduces the risk of an overly optimistic performance estimate that could arise if nearby time points were randomly assigned to both the training and test sets.
Practice: Create a 70%-30% chronological split of the data. Compare the training and test sets in terms of the distribution of
bike_count, and reflect on how changing the split may affect the difficulty of the prediction task.
Fitting Regression Models with a Transformed Response
We now fit regression models using sqrt_bike_count as the response. As the exploratory analysis showed, the square-root transformation makes the response distribution more symmetric and reduces the influence of very large rental counts. We also treat hour as a factor, since the daily demand pattern showed clear peaks and troughs rather than a simple linear trend over the course of the day.
We begin with a full regression model. It includes the weather-related predictors, the categorical variables season and holiday, the derived weekday feature, and hour as a factor. In addition, we include a quadratic term for temperature through I(temperature^2), allowing the model to capture a curved relationship between temperature and bike demand. This is plausible in practice, since both very cold and very warm conditions may reduce ridership. Although we created month during data preparation, we do not include it here because the data will be evaluated using a chronological split, and some month levels in the test period may not be represented in the training period.
Next, we fit a second regression model using stepwise selection based on the AIC criterion. Starting from the full model, this procedure searches for a simpler set of predictors by balancing goodness of fit against model complexity. Stepwise regression should not replace subject-matter reasoning, but it is useful here as a practical comparison to assess whether a slightly simpler model performs similarly to the full one.
stepwise_reg <- step(full_reg, direction = "both", trace = FALSE)To see which predictors are retained, we inspect the formula of the stepwise model.
The resulting formula shows that only one predictor was removed: wind_speed. This suggests that, after accounting for the other predictors, wind_speed did not improve the model enough to be retained under the AIC criterion. All other predictors from the full model remained in the stepwise specification.
Diagnostic Checking
Before comparing predictive performance, we examine whether the fitted regression model shows any clear diagnostic problems. A model may perform reasonably well in prediction while still showing residual patterns that suggest misspecification. We therefore inspect two standard diagnostic plots for the stepwise model: the Residuals vs Fitted plot and the Normal Q-Q plot.
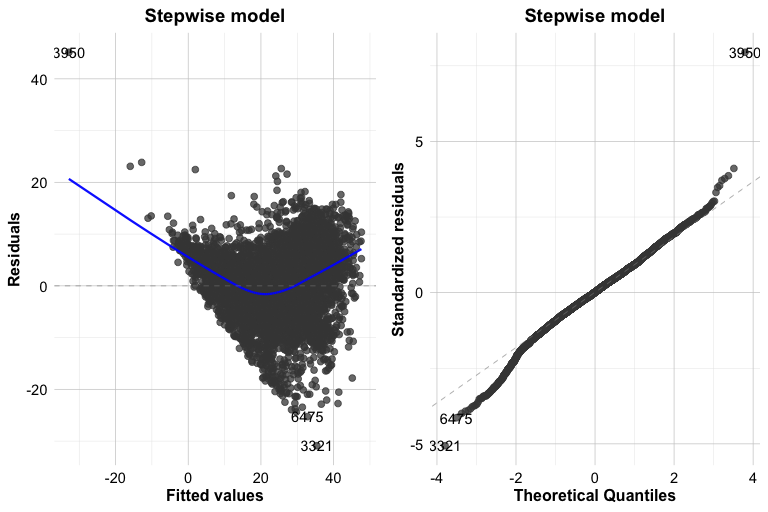
These plots help us assess whether the model fits the data reasonably well. In the Residuals vs Fitted plot, we look for residuals that are centered around zero without a strong systematic pattern. A visible curve would suggest remaining nonlinearity, while a funnel shape would suggest non-constant variance. In the Normal Q-Q plot, we assess whether the residuals are approximately normally distributed. Small departures from the reference line are not unusual, especially in a dataset of this size, but clear deviations in the tails deserve closer attention.
In this case, the residuals appear to be reasonably centered around zero, with no strong evidence of a pronounced curve or funnel shape. The Q-Q plot shows one clear point in the upper tail, corresponding to observation 3950 in the training set. This observation is not necessarily unusual in terms of its raw bike count, but it has a relatively large residual and therefore contributes to a departure from normality in the residual distribution. In a dataset of this size, a single such point is not necessarily a major concern, although it is still useful to inspect it more closely.
Practice: Examine observation 3950 in the training set by running
train_bike[3950, ]. Does it appear to be a data error, or does it look like a plausible but unusual hour of bike demand? What effect might such an observation have on the fitted regression model?
The corresponding diagnostic plots for the full regression model are very similar and lead to the same overall conclusion. For that reason, we do not reproduce them here. Curious readers may generate the same plots for full_reg and compare the two models directly.
Practice: Generate the diagnostic plots for
full_regand compare them with those of the stepwise model. Do the two models differ meaningfully in terms of residual pattern or normality?
Model Evaluation and Comparison
Because the response variable is numerical, we evaluate the fitted models using regression metrics. In particular, we use RMSE and \(R^2\) to compare the predictive performance of the full and stepwise models on the test set. As discussed in Chapter 8.9, these metrics summarize how closely the predicted values match the observed outcomes. We also use the Residual Standard Error (RSE) and adjusted \(R^2\) to compare the fitted models on the training data, and we complement the numerical summary with a plot of observed versus predicted bike rentals for the stepwise model.
We begin by comparing the fitted models on the training data using the Residual Standard Error and adjusted \(R^2\).
sqrt(sum(residuals(full_reg)^2) / df.residual(full_reg))
[1] 6.120529
sqrt(sum(residuals(stepwise_reg)^2) / df.residual(stepwise_reg))
[1] 6.120677summary(full_reg)$adj.r.squared
[1] 0.7377221
summary(stepwise_reg)$adj.r.squared
[1] 0.7377094The RSE and adjusted \(R^2\) values for the full and stepwise models are very close to each other. This suggests that both models fit the training data similarly. The fact that the stepwise model achieves nearly the same fit after removing wind_speed supports the idea that the simpler specification may be sufficient.
To assess predictive performance more directly, however, we must evaluate the models on the test set. Since the models were trained on sqrt_bike_count, we first generate predictions on the transformed scale and then convert them back to the original scale by squaring them. Because a regression model on the square-root scale can occasionally produce slightly negative predictions, we truncate such values at zero before squaring.
We now compute RMSE and \(R^2\) on the original scale of hourly bike rentals.
reg_metrics <- function(actual, predicted, model) {
data.frame(
Model = model,
RMSE = sqrt(mean((actual - predicted)^2)),
R2 = 1 - sum((actual - predicted)^2) / sum((actual - mean(actual))^2)
)
}
rbind(
reg_metrics(test_bike$bike_count, pred_full, "Full model"),
reg_metrics(test_bike$bike_count, pred_stepwise, "Stepwise model")
)
Model RMSE R2
1 Full model 335.2158 0.6871619
2 Stepwise model 333.8172 0.6897669The test-set RMSE and \(R^2\) values for the full and stepwise models are also very close, indicating that the two models have nearly the same predictive performance on unseen data. At the same time, the stepwise model performs slightly better, with a slightly lower RMSE and a slightly higher \(R^2\). This suggests that removing wind_speed does not reduce predictive accuracy and may even improve it marginally. Taken together, these results support the stepwise model as the preferred specification, since it is slightly simpler while performing at least as well as the full model.
To complement the numerical evaluation, we also plot the observed and predicted bike rentals for the stepwise model on the test set.
ggplot(
data.frame(observed = test_bike$bike_count, predicted = pred_stepwise),
aes(x = observed, y = predicted)
) +
geom_point() +
geom_abline(intercept = 0, slope = 1, linetype = "dashed", colour = "firebrick3") +
labs(x = "Observed bike rentals", y = "Predicted bike rentals")
The points lie reasonably close to the diagonal reference line, especially for observed bike counts below about 1500, which suggests that the stepwise model predicts moderate demand levels fairly well. For larger observed values, however, the points tend to fall below the diagonal, indicating that the model slightly underpredicts the highest-demand hours. This pattern suggests that the model captures the overall structure of bike demand well, while still having more difficulty with extreme demand levels.
This case study illustrates an important lesson about regression modeling. Predictive performance does not depend only on the choice of method. It also depends on how thoughtfully we represent the structure of the data. By using a transformed response, treating hour as a factor, respecting the temporal ordering of the observations, and allowing a nonlinear effect for temperature, we obtain a regression model that is both interpretable and practically useful.
Practice: Repeat the analysis using a 70% training set and a 30% test set, again preserving the chronological order of the data. Compute RMSE and \(R^2\) for both models on the new test set, and compare the results with those obtained from the 80%-20% split. Does changing the partition alter which model appears preferable?
10.10 Chapter Summary and Takeaways
In this chapter, we introduced regression analysis as a core framework for modeling continuous outcomes. We began with simple linear regression and then extended the discussion to multiple regression, showing how additional predictors can improve our ability to explain variation in a response variable. Along the way, we emphasized that regression serves several purposes at once: it can be used for prediction, for interpretation, and for statistical inference about the role of individual predictors.
We also examined how to evaluate regression models from several complementary perspectives. Measures such as the residual standard error, \(R^2\), and adjusted \(R^2\) help us assess model fit, while hypothesis tests help us judge whether predictors contribute information beyond what is explained by the others. At the same time, we saw that good numerical fit alone is not enough: a useful regression model should also be interpretable, appropriately specified, and well aligned with the structure of the data.
To move beyond strictly linear relationships, we introduced polynomial regression as a practical way to model curvature while remaining within the familiar linear modeling framework. We also examined stepwise regression as a tool for comparing alternative predictor sets and selecting a more parsimonious model. Throughout the chapter, we stressed that these modeling choices should be guided not only by summary statistics, but also by diagnostic checks that reveal whether important assumptions appear reasonable.
The bike rental case study brought these ideas together in a realistic setting. There, we showed how response transformation, feature construction, time-aware data partitioning, model comparison, and diagnostic analysis all contribute to effective regression modeling in practice. The broader lesson is that successful modeling does not come from choosing the most complicated method available, but from choosing a model that is appropriate for the question, the data, and the intended use of the results.
This chapter therefore reinforces an important principle of the Data Science Workflow: reliable modeling requires both statistical tools and careful judgment. Regression models provide a structured way to quantify relationships, assess uncertainty, and generate interpretable predictions when the response is continuous. In the next chapter, we extend these ideas to situations in which the response is no longer continuous, turning to generalized regression models for binary and count outcomes.
10.11 Exercises
These exercises reinforce the main ideas of the chapter by combining conceptual understanding, interpretation of regression output, model comparison, diagnostic reasoning, and practical implementation in R. The hands-on sections use the house, insurance, and bike_demand datasets from the liver package.
Conceptual Questions
In a simple linear regression model, how should we interpret the intercept and the slope?
What does the \(R^2\) value tell us about a regression model?
Why is adjusted \(R^2\) often more informative than \(R^2\) when comparing models with different numbers of predictors?
What does the residual standard error measure, and how does it differ from \(R^2\)?
Why is it useful to distinguish between interpretation and prediction when evaluating a regression model?
What is multicollinearity, and why can it make regression coefficients harder to interpret?
What is the purpose of stepwise regression, and what are its limitations?
Why is polynomial regression still considered a linear model?
What kinds of patterns in a Residuals vs Fitted plot might suggest that a linear model is inadequate?
Why should regression diagnostics be viewed as part of model building rather than as a final checklist applied after fitting the model?
Hands-On Practice: Regression Analysis with with house
data(house, package = "liver")Use the
partition()function introduced earlier in the book to split thehousedata into training and test sets. Use 80% of the observations for training and 20% for testing, and store the results astrain_dataandtest_data.Fit the full regression model on the training data and store it as
full_model_train:
full_model_train = lm(unit_price ~ ., data = train_data)Apply stepwise regression to
full_model_trainand store the result asstepwise_model. Which predictor or predictors are removed?Fit the polynomial regression model below using the training data:
Compare
full_model_train,stepwise_model, andpoly_reg_houseusing the residual standard error and adjusted \(R^2\) on the training data. What do these measures suggest, and what do they not tell you about performance on unseen data?Use the three fitted models to predict
unit_pricefor the test set. Compute the mean squared error (MSE) for each model. Which model performs best on unseen data?Compare the test-set MSE of
stepwise_modelandpoly_reg_house. Does allowing curvature inhouse_ageimprove predictive performance enough to justify the added complexity?Create a plot showing the relationship between
house_ageandunit_price, and add fitted curves from both a linear and a quadratic model based only onhouse_age. What does this comparison suggest about the need for a nonlinear term?Compare the Residuals vs Fitted plots of
stepwise_modelandpoly_reg_house. Which model shows less evidence of non-linearity?Examine the Normal Q-Q, Scale-Location, and Residuals vs Leverage plots for
poly_reg_house. Do the diagnostics suggest any serious problems?Observation 271 was highlighted in the chapter. Does it still stand out in the diagnostic plots for
poly_reg_housefitted on the training data? What can you say about its residual size, leverage, and possible influence?Extend
poly_reg_houseby adding a cubic term,I(house_age^3). Compare the cubic model with the quadratic model using both adjusted \(R^2\) on the training data and MSE on the test data. Does the cubic term appear to improve the model enough to justify the extra complexity?Based on your comparisons, which of the three models would you recommend if the goal is prediction, and which would you recommend if the goal is interpretation? Explain your reasoning.
Hands-On Practice: Regression Analysis with diamonds
Use the cleaned version of the diamonds dataset prepared in Chapter 3.
Which variable is the natural response for a regression analysis in this dataset, and which variables seem like plausible predictors?
Use the
partition()function introduced earlier in the book to split the cleaneddiamondsdata into training and test sets. Use 80% of the observations for training and 20% for testing.Fit a simple linear regression model on the training data predicting
pricefromcarat. Store it assimple_model_diamonds. Interpret the estimated intercept and slope.Create a scatter plot of
priceversuscaratand add the fitted regression line. Does a straight-line relationship appear reasonable?Fit a multiple regression model on the training data predicting
priceusingcarat,cut,color, andclarity. Store it asfull_model_diamonds.Compare the simple and multiple regression models using the residual standard error and adjusted \(R^2\) on the training data. What do these measures suggest?
Apply stepwise regression to
full_model_diamondsand store the result asstepwise_model_diamonds. Which predictors are retained in the final specification?Starting from your main diamonds model, add a quadratic term for
carat, that is,I(carat^2). Does this nonlinear term appear useful?Compare your main diamonds models on the test set using mean squared error (MSE). Which model performs best on unseen data?
Produce the standard diagnostic plots for your preferred diamonds model. Do they suggest any serious problems with non-linearity, non-constant variance, non-normal residuals, or influential observations?
Based on your results, which diamonds model would you recommend if the goal is prediction, and which would you recommend if the goal is interpretation? Explain your reasoning.
Case Study Reflection: Predicting Bike Rental Demand
data(bike_demand, package = "liver")In the chapter, why was it important to restrict the analysis to observations with
functioning_day == "yes"before fitting the regression models?Why was a chronological 80%-20% split more appropriate than a random split for the bike demand case study?
What was the motivation for modeling
sqrt_bike_countinstead ofbike_countdirectly? In your answer, comment on both distributional shape and model stability.The stepwise model removed only
wind_speed. What does this suggest about the relationship between model simplicity and predictive performance in this case study?The full and stepwise bike-demand models had very similar diagnostics and test-set performance. What broader lesson does this give about choosing between competing regression models?
Compare the goals of prediction and explanation in the bike demand case study. If the audience were city planners rather than modelers, would you still prefer the same final model? Explain your reasoning.
Self-Reflection
- Think of a real-world problem involving a continuous outcome, such as housing prices, medical costs, product demand, or environmental exposure. Which regression approach from this chapter would you begin with: simple linear regression, multiple linear regression, or a model with non-linear terms? Explain your choice.