library(ggplot2)
data(diamonds)
str(diamonds)
tibble [53,940 × 10] (S3: tbl_df/tbl/data.frame)
$ carat : num [1:53940] 0.23 0.21 0.23 0.29 0.31 0.24 0.24 0.26 0.22 0.23 ...
$ cut : Ord.factor w/ 5 levels "Fair"<"Good"<..: 5 4 2 4 2 3 3 3 1 3 ...
$ color : Ord.factor w/ 7 levels "D"<"E"<"F"<"G"<..: 2 2 2 6 7 7 6 5 2 5 ...
$ clarity: Ord.factor w/ 8 levels "I1"<"SI2"<"SI1"<..: 2 3 5 4 2 6 7 3 4 5 ...
$ depth : num [1:53940] 61.5 59.8 56.9 62.4 63.3 62.8 62.3 61.9 65.1 59.4 ...
$ table : num [1:53940] 55 61 65 58 58 57 57 55 61 61 ...
$ price : int [1:53940] 326 326 327 334 335 336 336 337 337 338 ...
$ x : num [1:53940] 3.95 3.89 4.05 4.2 4.34 3.94 3.95 4.07 3.87 4 ...
$ y : num [1:53940] 3.98 3.84 4.07 4.23 4.35 3.96 3.98 4.11 3.78 4.05 ...
$ z : num [1:53940] 2.43 2.31 2.31 2.63 2.75 2.48 2.47 2.53 2.49 2.39 ...3 Data Preparation in Practice: From Raw Data to Insight
Divide each difficulty into as many parts as is feasible and necessary to resolve it.
In real-world settings, data rarely arrive in a clean, analysis-ready format. They often contain missing values, extreme observations, inconsistent entries, and nonstandard codes that reflect how they were collected rather than how they will be analyzed. While curated teaching datasets are useful for learning, they can give the misleading impression that data science begins only after the difficult preparation work has already been done.
This chapter focuses on data preparation as a core stage of the Data Science Workflow. Regardless of how sophisticated a statistical method or machine learning algorithm may be, its results depend on the quality, consistency, and structure of the data used to train or evaluate it. Preparing data is therefore not a peripheral technical step, but an analytical activity that shapes model performance, interpretability, and credibility.
Throughout the chapter, we develop practical strategies for identifying irregularities in data and deciding how they should be handled. We examine feature types, implausible values, outliers, missing values, placeholder codes, and simple imputation methods. We also consider how variables are represented, recoded, or simplified so that they better reflect the analytical question. The emphasis is not on applying rules mechanically, but on making preparation decisions that are justified by the structure of the data and the goal of the analysis.
Data preparation naturally overlaps with later stages of the workflow, but the focus differs across chapters. In this chapter, we focus on correcting, recoding, and structuring data. In Chapter 4, we explore patterns and relationships through exploratory data analysis. In Chapter 6, we prepare data for specific modeling algorithms and evaluation design. In practice, these stages are often revisited iteratively rather than completed in a strict sequence.
What This Chapter Covers
This chapter develops data preparation as a sequence of practical decisions that make a dataset more coherent, reliable, and suitable for later analysis. We begin with feature types and their representation in R, then examine outliers and implausible values, distinguishing rare but meaningful observations from values that likely reflect data errors.
We then turn to missing values, placeholder codes, and imputation strategies, including median imputation and random sampling imputation. The chapter also discusses how sparse or high-cardinality categorical features can be simplified when they create unnecessary complexity. We use the diamonds dataset from the ggplot2 package to illustrate individual preparation techniques and the adult dataset from the liver package to show how these techniques can be combined in a more realistic workflow. Together, these examples show how data preparation transforms raw data into a documented and analytically useful form before exploratory analysis and modeling begin.
3.1 Feature Types and Data Representation
Before detecting outliers, recoding missing values, or simplifying categories, we need to understand what each variable represents. Feature type determines which summaries are meaningful, which visual tools are appropriate, and which preparation steps are justified. A numerical feature can be summarized by measures such as the mean or median, while a categorical feature is usually summarized by frequencies or proportions. Treating these feature types interchangeably can lead to misleading summaries and inappropriate modeling choices.
We use the diamonds dataset from the ggplot2 package to introduce these ideas. The dataset provides a controlled setting in which feature types, implausible values, and imputation choices can be demonstrated clearly. Each row represents a diamond, described by physical measurements such as carat weight and dimensions, quality ratings such as cut, color, and clarity, and the price in US dollars. We return to this dataset in Chapter 10, where these features are used in a regression modeling context.
We begin by loading the dataset and inspecting its structure:
The output shows that the dataset contains 53940 observations and 10 variables. The numerical variables include carat, depth, table, price, and the physical dimensions x, y, and z. These variables measure quantities such as weight, proportions, dimensions, and price.
The categorical variables cut, color, and clarity describe quality ratings. They are ordinal because their levels have a meaningful order, although the differences between adjacent levels should not be interpreted as equal numerical distances.
Numerical and Categorical Features
At a high level, most features used in data science can be grouped into two broad types: numerical and categorical features. Each type can be divided into common subtypes. Figure 3.1 summarizes this classification.
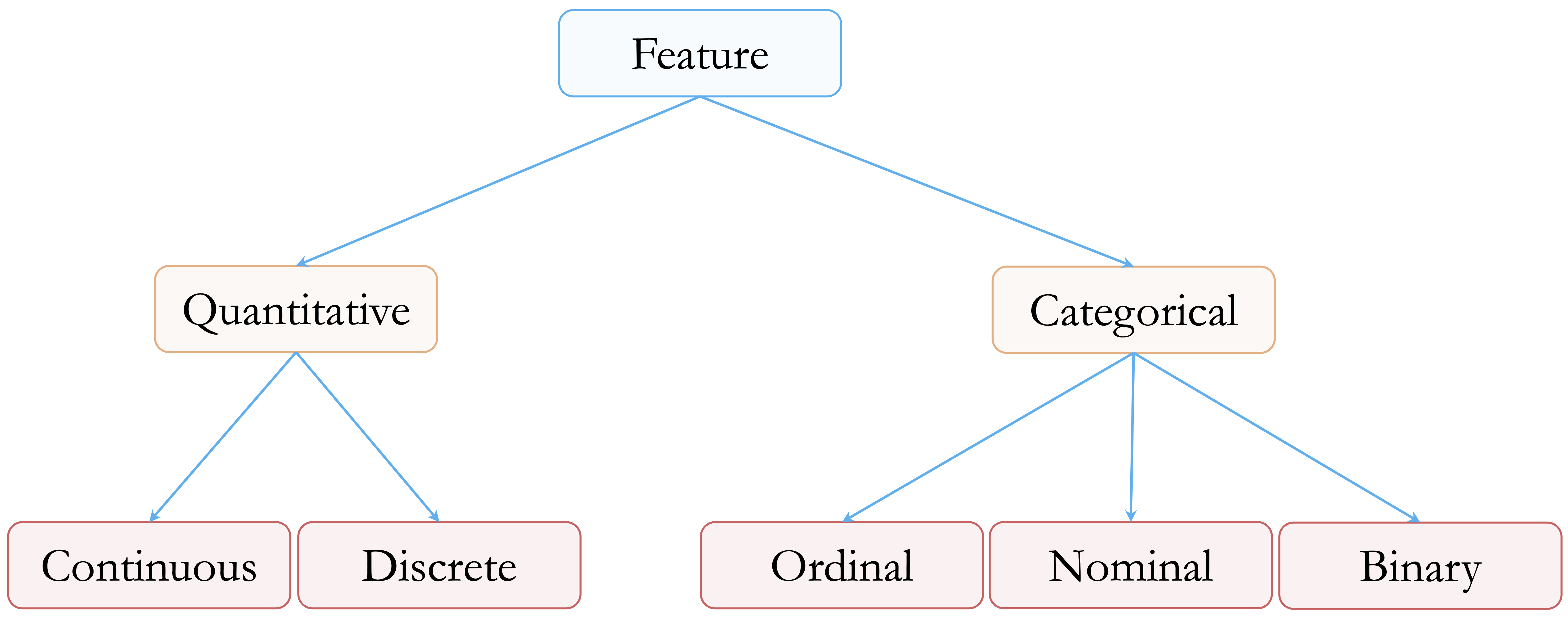
Numerical features represent measurable quantities. Continuous features can take many possible values within a range, such as diamond price, carat weight, or physical dimensions. Discrete numerical features take countable values, often integers, such as the number of purchases, website visits, or product defects. Although the diamonds dataset does not contain discrete numerical features, such features are common in applied data science.
Categorical features describe group membership rather than numerical magnitude. Nominal features represent categories without an inherent order, such as product type, region, or blood group. Ordinal features have a meaningful order, although the spacing between levels is not necessarily uniform. In the diamonds dataset, cut, color, and clarity are ordinal categorical features because their levels represent ordered quality grades. For example, color ranges from D, the most colorless grade, to J, the least colorless grade in this dataset. Binary features are categorical features with exactly two levels, such as yes/no, success/failure, or churn/no churn.
This distinction matters because preparation choices depend on feature type. Outlier detection is usually meaningful for numerical features, but not for unordered categorical features. Imputation for a numerical feature might use the median or a sampled observed value, while imputation for a categorical feature might use the mode or a sampled category. Similarly, simplifying sparse categories is relevant for categorical features, whereas transformations such as logarithms or square roots apply to numerical features.
How R Represents Feature Types
In R, the way a variable is stored affects how it is summarized, plotted, and used in models. Numerical variables are commonly stored as numeric or integer vectors. Categorical variables are often stored as factor objects. A factor can be unordered, as with nominal categories, or ordered, as with ordinal categories. Checking both the meaning of a variable and its representation in R is therefore an important part of data preparation.
The str() output for the diamonds dataset shows that cut, color, and clarity are stored as ordered factors. This is important because their levels carry information about quality. We can inspect the representation of cut directly:
typeof(diamonds$cut)
[1] "integer"
class(diamonds$cut)
[1] "ordered" "factor"
is.ordered(diamonds$cut)
[1] TRUE
levels(diamonds$cut)
[1] "Fair" "Good" "Very Good" "Premium" "Ideal"The output shows that cut has the classes ordered and factor, with levels ranging from Fair to Ideal. The result of typeof() also reminds us that factors are stored internally using integer codes. These internal codes should not be interpreted as numerical measurements. They are simply R’s way of representing category membership.
An ordered factor remains categorical, even when its levels follow a natural order. For example, the ordering from Fair to Ideal reflects increasing cut quality, but it does not imply that the difference between Fair and Good is numerically equal to the difference between Premium and Ideal. The same caution applies to many ordinal variables in applied datasets, such as education level, satisfaction rating, or disease severity.
It is therefore useful to distinguish between the conceptual type of a variable and its technical representation in R. A variable may be conceptually categorical but stored as text, or conceptually ordinal but stored as an unordered factor. Before applying preparation steps, we should check both what the variable means and how R has stored it. This habit helps prevent inappropriate summaries, misleading visualizations, and avoidable modeling errors.
Practice: Use the
diamondsdataset to inspect how different variables are represented in R. Applytypeof(),class(), andsummary()toprice,carat,cut,color, andclarity. Then applylevels()tocut,color, andclarity. Compare the results for numerical and ordered categorical variables, and explain whycutshould not be treated as a numerical measurement, even though its levels are ordered.
With the feature types in the diamonds dataset clarified, we can now examine one of the most common preparation challenges for numerical variables: identifying outliers and implausible values.
3.2 Outliers and Implausible Values
Outliers are observations that deviate markedly from the overall pattern of a dataset. They may arise from data entry errors, unusual measurement conditions, or genuinely rare but informative cases. Regardless of their origin, outliers can strongly influence summaries, visualizations, and statistical or machine learning models.
The central challenge is not only to identify extreme values, but also to decide what they represent. A useful distinction is between outliers, data errors, and rare observations. An outlier is a value that appears unusual relative to the rest of the data. A data error is a value that is incompatible with the measurement process or with the meaning of the variable. A rare observation is unusual but valid, and may contain important information.
This distinction matters because different types of unusual values require different responses. A diamond width of zero millimeters is not physically meaningful and should be treated as an impossible measurement. By contrast, an unusually expensive diamond may be rare but valid. Similarly, a large value of capital_gain in the adult dataset may reflect a genuine financial event rather than a mistake. Treating all unusual values as errors can remove meaningful information, while retaining clearly impossible values can distort analysis.
Outlier detection should therefore be understood as a diagnostic step, not as an automatic cleaning rule. Visual tools and numerical summaries can help identify values that deserve closer inspection, but the final decision should be guided by the meaning of the variable, the data collection process, and the goal of the analysis.
Detecting Outliers with Visual Tools
Visualization provides a natural starting point for detecting outliers and implausible values. Different plots highlight different aspects of the data. Boxplots summarize the spread of a variable and flag values far from the central range. Histograms show the full distribution and can reveal gaps, spikes, skewness, or isolated values. Scatter plots are useful when we need to examine whether an unusual value is also unusual in relation to another variable.
Boxplots use the interquartile range (IQR) to flag potential outliers. Values lying more than 1.5 times the IQR below the first quartile or above the third quartile are often displayed as individual points. This rule is useful for screening, but it should not be interpreted as proof that a value is wrong.
To illustrate visual outlier detection, we examine the variable y in the diamonds dataset, which records diamond width in millimeters. We first compare a full-scale boxplot with a zoomed-in version:
ggplot(data = diamonds) +
geom_boxplot(aes(y = y)) +
labs(title = "Full scale", y = "Diamond width (mm)")
ggplot(data = diamonds) +
geom_boxplot(aes(y = y)) +
coord_cartesian(ylim = c(0, 15)) +
labs(title = "Zoomed view", y = "Diamond width (mm)")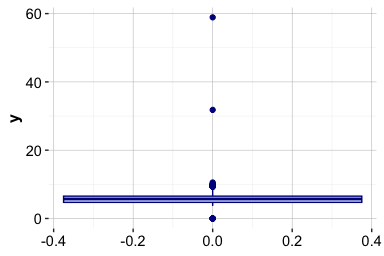
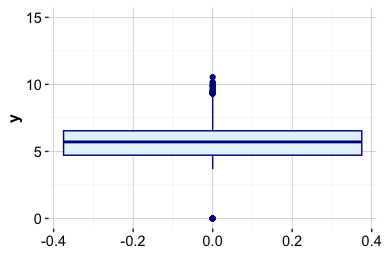
The full-scale boxplot shows that a small number of extreme values stretch the vertical axis and compress the main body of the distribution. The zoomed view shows that most diamond widths lie between approximately 2 and 6 mm, with a few observations far outside the usual range. The coord_cartesian() function changes only the displayed range; it does not remove observations from the data.
Histograms provide a complementary view because they show how frequently values occur across the range of a variable. We again compare the full distribution with a zoomed-in view of the vertical axis:
ggplot(data = diamonds) +
geom_histogram(aes(x = y), binwidth = 0.5) +
labs(title = "Full scale", x = "Diamond width (mm)", y = "Count")
ggplot(data = diamonds) +
geom_histogram(aes(x = y), binwidth = 0.5) +
coord_cartesian(ylim = c(0, 20)) +
labs(title = "Zoomed count scale", x = "Diamond width (mm)", y = "Count")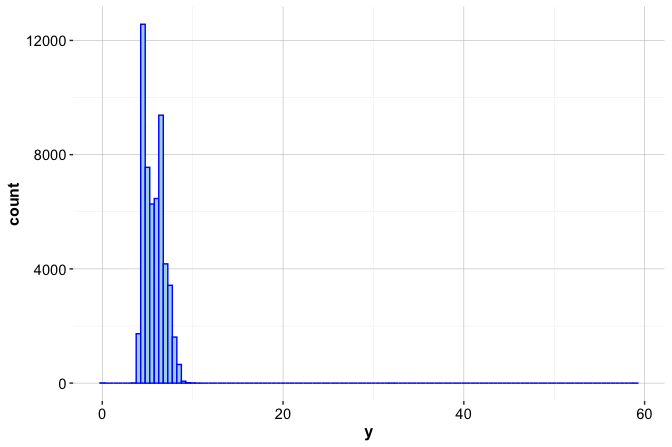
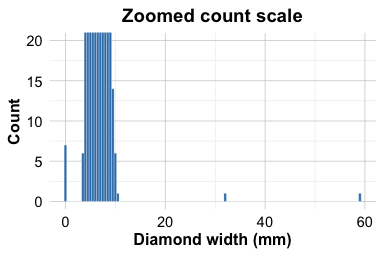
The full-scale histogram shows that most values are concentrated between approximately 2 and 6 mm. The zoomed count scale reveals seven zero values and two unusually large values, one slightly above 30 mm and another close to 60 mm. A width of zero is physically impossible, while very large widths should be inspected together with the other dimensions before any preparation decision is made.
Before changing the data, we inspect the affected rows:
diamonds[
diamonds$y == 0 | diamonds$y > 30,
c("carat", "cut", "color", "clarity", "x", "y", "z", "price")
]
# A tibble: 9 × 8
carat cut color clarity x y z price
<dbl> <ord> <ord> <ord> <dbl> <dbl> <dbl> <int>
1 1 Very Good H VS2 0 0 0 5139
2 1.14 Fair G VS1 0 0 0 6381
3 2 Premium H SI2 8.09 58.9 8.06 12210
4 1.56 Ideal G VS2 0 0 0 12800
5 1.2 Premium D VVS1 0 0 0 15686
6 2.25 Premium H SI2 0 0 0 18034
# ℹ 3 more rowsThis step is important because outliers should not be treated by looking at one variable in isolation. For physical measurements such as x, y, and z, an implausible value in one dimension may indicate that the entire record requires closer inspection. In this case, the zero values of y are accompanied by zero values of both x and z, which strongly suggests that the physical dimensions were not recorded correctly for these diamonds. The unusually large values of y are also inconsistent with the corresponding values of x and z, suggesting that they are more likely to reflect measurement or recording errors than rare but valid observations. This example illustrates the importance of examining outliers in context before deciding how to handle them.
Practice: Apply the same visual checks to the variables
xandz, which represent diamond length and depth. Use both boxplots and histograms, and compare the results with those fory. Which values appear merely unusual, and which values appear physically implausible?
Strategies for Handling Outliers
Once unusual values have been identified, the next step is to decide how they should be handled. There is no universally correct strategy. The appropriate response depends on whether the value is impossible, suspicious but plausible, or rare and informative. It also depends on the data collection process, the analytical objective, and the type of model or summary that will be used later.
When an unusual value is valid and potentially informative, it should usually be retained. In fraud detection, for example, extreme values may be precisely the cases of interest. Similarly, in the adult dataset examined later in this chapter, unusually large values of capital_gain may correspond to genuine financial events rather than errors. In such cases, the aim is not to remove the value, but to understand its influence. If the unusual value may carry useful information, an additional indicator variable can sometimes be created to flag its presence.
When there is strong evidence that a value is erroneous, a different response is needed. Implausible measurements, such as a diamond width of zero or a negative value for a quantity that cannot be negative, should not be silently retained. Such values may be recoded as NA, corrected if reliable information is available, or removed only when the affected record cannot be used responsibly. Removing observations should generally be treated as a last resort, since it can reduce information and introduce bias if applied too broadly.
Some unusual values are not isolated errors but part of a strongly skewed distribution. In these cases, transformations such as logarithms or square roots, robust summaries, winsorization, or models that are less sensitive to extreme values may be more appropriate than deletion. Whatever strategy is used, it should be justified and documented. The goal is not to make the dataset look neat, but to make preparation decisions that are defensible, transparent, and consistent with the purpose of the analysis.
Example: Cleaning Diamond Dimensions
We now apply these principles to the physical dimensions in the diamonds dataset. The variable y contains seven zero values and two unusually large values, one slightly above 30 mm and another close to 60 mm. Because y measures diamond width, a value of zero is physically impossible. Values above 30 mm are also implausible in the context of this dataset, especially when compared with the corresponding values of x and z.
In a full analysis, we would inspect the full records carefully before deciding whether to recode one dimension or remove affected observations entirely. Here, the goal is to demonstrate a transparent cleaning workflow: identify unusual values, inspect the affected records, decide whether they are plausible, and document the preparation step. Based on the earlier inspection, we treat values of y equal to zero or greater than 30 as implausible measurements.
Rather than deleting the affected observations, we create a cleaned version of the dataset in which these implausible measurements are recoded as missing values. This preserves the records while marking the problematic entries for later handling.
The condition y == 0 | y > 30 identifies values that are physically impossible or implausibly large for this variable. These values are replaced with NA, while all other values of y are retained.
We can verify the result by comparing the summaries of the original and cleaned variables:
summary(diamonds$y)
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.000 4.720 5.710 5.735 6.540 58.900
summary(diamonds_clean$y)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
3.680 4.720 5.710 5.734 6.540 10.540 9The cleaned version records nine values of y as missing. The largest implausible width values no longer dominate the summary, but the affected observations remain in the dataset. This distinction is important: the problematic measurements have been recoded, not silently discarded. In the next section, we use this cleaned variable to introduce missing-value handling and imputation.
Practice: Extend the same cleaning logic to
xandz. Identify values that are zero or physically implausible, inspect the affected rows, recode problematic measurements asNA, and compare the summaries before and after cleaning.
3.3 Missing Values and Imputation
Missing values are more than empty cells in a dataset. They often reflect how data were collected, which measurements were unavailable, or which information was not recorded under certain conditions. If missing values are ignored or handled mechanically, they can distort summaries, obscure patterns, and lead to misleading models.
In R, missing values are usually represented by NA. In practice, however, missingness may also appear through nonstandard placeholder codes such as -1, 999, "unknown", "missing", or "?". These values require careful inspection before analysis. Some placeholders indicate genuinely missing information and should be recoded as NA, while others encode meaningful conditions that should be retained.
A placeholder code should therefore not be recoded automatically. The same code can have different meanings in different datasets. For example, a value of -1 may indicate missing information in one dataset but a meaningful structural condition in another. In the bank dataset, the value -1 in pday indicates that a client was not previously contacted. This is not simply missing information; it records a meaningful condition. By contrast, the "?" values in the adult dataset later in this chapter represent nonstandard missing-value codes that should be recoded as NA.
A useful habit is to inspect summaries, unique values, and missing-value counts before applying any cleaning step:
These checks help distinguish genuine missing values from valid but unusual codes. This distinction matters because recoding a meaningful value as missing can remove information, while failing to recode a placeholder code can distort summaries, visualizations, and downstream models.
Once missing values have been identified, the next question is how they should be handled. In descriptive work, the aim is often to summarize the observed data transparently and understand where information is incomplete. In predictive modeling, missing-value handling must be integrated into the modeling workflow. In particular, imputation rules should usually be learned from the training data and then applied to validation or test data. This prevents information from the validation or test set from influencing data preparation. Chapter 6 returns to this issue when discussing data setup for modeling.
Several strategies can be used to handle missing values. Some methods replace missing entries with simple summaries, such as the mean, median, or mode. Others use random sampling from the observed values or estimate missing values from relationships with other variables. These approaches differ in complexity, assumptions, and in how much of the original variability they preserve. Before choosing among them, we first consider why values may be missing, since the missingness mechanism affects how reasonable an imputation strategy is likely to be.
Missingness Mechanisms
Missingness is often described using three broad mechanisms: missing completely at random, missing at random, and missing not at random. These mechanisms help clarify what assumptions are being made when incomplete data are analyzed or imputed. They do not provide labels that can be verified automatically from the data alone, but they offer a useful framework for thinking about the source of missing values.
Data are missing completely at random when the probability that a value is missing does not depend on either observed or unobserved information. For example, measurements lost because of a random technical failure may approximately follow this pattern. Under this mechanism, the observed cases can be treated as a random subset of the full data, although information is still lost.
Data are missing at random when the probability of missingness depends on observed variables, but not on the missing value itself after those variables are taken into account. For instance, income may be more often missing for younger respondents, but within each age group the missingness may not depend further on the income value. In this case, observed variables can help explain the missingness and support more informed imputation.
Data are missing not at random when the probability of missingness depends on the unobserved value itself. Income again provides a useful example: individuals with very high incomes may be less willing to report them. This type of missingness is more difficult to handle because the missing values are systematically related to information that is not observed.
The distinction among these mechanisms matters because imputation is not only a computational step. It also involves assumptions about how the missing values relate to the observed data. If missingness is approximately random, simple methods may be adequate for exploratory purposes. If missingness is related to observed variables, methods that use those variables may be more appropriate. If missingness depends on the unobserved values themselves, any imputation strategy should be interpreted with particular caution.
In practice, we rarely know the true missingness mechanism with certainty. The aim is therefore not to assign a definitive label, but to think carefully about the data collection process, inspect patterns of missingness, and state the assumptions behind the chosen method.
Simple Imputation Methods
Imputation replaces missing values with plausible values derived from the observed data. Simple imputation methods use a single summary of the variable with missing entries. They are easy to implement and explain, which makes them useful for teaching, exploratory work, and simple preprocessing tasks. However, they do not recover the true missing values and do not reflect uncertainty about what those values might have been.
For numerical variables, common choices are mean and median imputation. Mean imputation replaces missing values with the average of the observed values and may be reasonable for approximately symmetric distributions. Median imputation is often more robust for skewed variables because it is less affected by extreme values. For categorical variables, mode imputation replaces missing values with the most frequently observed category.
The relationship between distribution shape and summary-based imputation is shown in Figure 3.3. In symmetric distributions, the mean and median are close together. In skewed distributions, the mean is pulled toward the longer tail, while the median remains more stable.
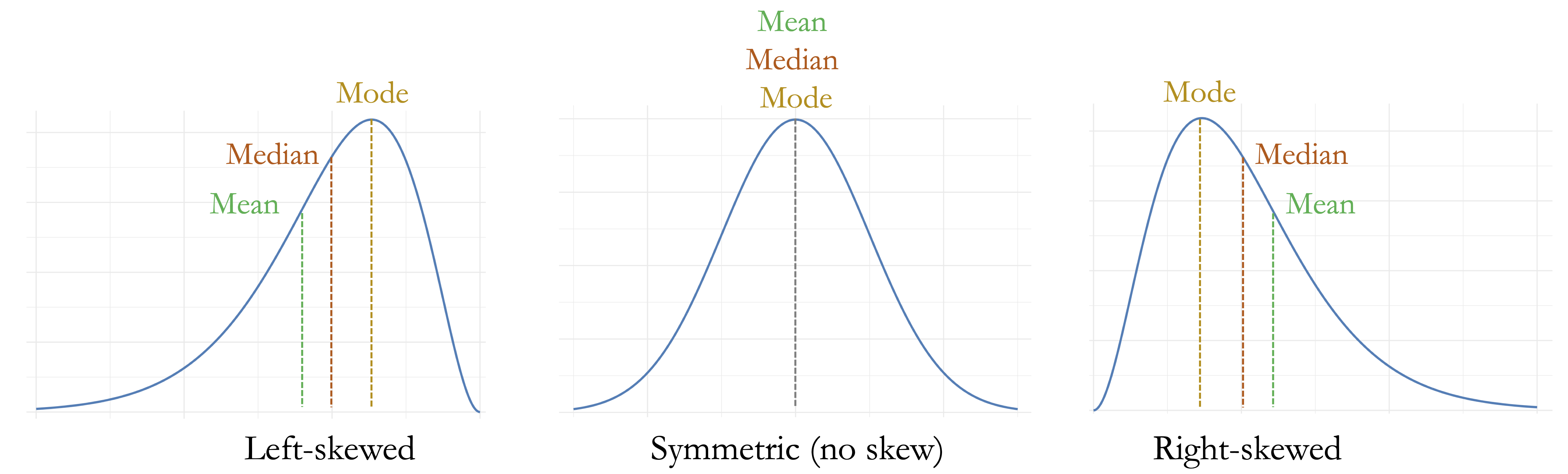
The choice of imputation method should reflect both the feature type and the distribution of the observed values. Mean imputation is sensitive to extreme values, while median imputation is usually more stable for skewed numerical variables. Mode imputation is simple and interpretable for categorical variables, but it can overrepresent the most frequent category, especially when missingness is not negligible.
The main limitation of these methods is that they replace all missing values in a variable with the same number or category. This can reduce variability and weaken relationships with other variables. For this reason, simple imputation should be used with care when missingness is substantial or when relationships among variables are central to the analysis. The next subsection considers alternatives that preserve more variability or use information from other features.
Random Sampling and Model-Based Imputation
Random sampling imputation replaces each missing value by drawing from the observed values of the same variable. Unlike mean, median, or mode imputation, it does not insert the same value repeatedly. This helps preserve the marginal distribution of the variable, including its spread and shape.
However, random sampling imputation has two important limitations. First, it introduces randomness, so a seed should be set when reproducibility is required. Second, it samples from the observed distribution of one variable only and does not use information from related variables. For example, randomly imputing diamond width from the observed values of y does not use information from carat, x, z, or price.
Model-based imputation takes a different approach by using relationships among variables to estimate missing values. Examples include regression-based imputation, tree-based imputation, \(k\)-nearest-neighbor imputation, and methods implemented in packages such as Hmisc and mice. These methods can produce more realistic imputations when variables are strongly related, but they require stronger assumptions, additional modeling choices, and more careful implementation.
An important extension is multiple imputation, which creates several completed versions of the dataset and combines results across them. This approach is especially useful for statistical inference because it reflects uncertainty about the missing values. In this chapter, we focus on simpler methods because the goal is to introduce the logic of imputation rather than the full theory of missing-data analysis. More advanced methods should be treated as part of a complete analysis plan rather than as automatic preprocessing steps.
Example: Imputing Diamond Width
We now return to the cleaned diamonds_clean dataset created in the previous section. Implausible values of y, including zero widths and values above 30 mm, were recoded as NA. The next question is how these missing values should be handled.
We begin by examining a numerical summary of the cleaned variable:
summary(diamonds_clean$y)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
3.680 4.720 5.710 5.734 6.540 10.540 9The summary confirms that nine values are now recorded as missing. It also suggests a mildly right-skewed distribution, with the mean slightly larger than the median. Since the number of missing values is small, median imputation provides a simple first approach for illustrating how missing entries can be filled.
We use the impute() function from the Hmisc package to replace the missing values with the median of the observed values:
This code creates a new variable, y_median, rather than overwriting y. Keeping the cleaned variable y unchanged preserves the preparation history and allows different imputation strategies to be compared.
Median imputation fills each missing value with the same summary value. This makes the method simple and reproducible, but it also introduces repeated values and slightly reduces variability. As an alternative, we use random sampling imputation, which draws replacement values from the observed nonmissing values of y. To make the result reproducible, we set a seed before sampling:
Random sampling imputation preserves the marginal spread of the variable more directly than median imputation. However, it does not use information from related variables such as carat, x, z, or price.
Because only nine values were imputed, the difference between the two methods is easiest to see by inspecting the affected observations directly:
missing_y <- is.na(diamonds_clean$y)
data.frame(
price = diamonds_clean$price[missing_y],
y_median = as.numeric(diamonds_clean$y_median[missing_y]),
y_random = as.numeric(diamonds_clean$y_random[missing_y])
)
price y_median y_random
1 5139 5.71 4.85
2 6381 5.71 6.63
3 12210 5.71 5.31
4 12800 5.71 5.70
5 15686 5.71 6.51
6 18034 5.71 6.00
7 2075 5.71 4.43
8 2130 5.71 6.25
9 2130 5.71 4.30The table shows the main difference between the two methods. Median imputation assigns the same replacement value to every missing observation, while random sampling imputation assigns values drawn from the observed distribution. These sampled values vary across observations, but they should still be interpreted as plausible replacements rather than recovered true measurements.
This example uses the full dataset to illustrate the mechanics of imputation. In predictive modeling, however, imputation rules should usually be learned from the training set and then applied to validation or test data, rather than estimated from the full dataset before partitioning. This prevents information from the validation or test set from influencing the preparation of the training data.
Practice: Compare median imputation and random sampling imputation for the variables
xandz. After recoding physically implausible values asNA, create imputed versions of each variable and compare their summaries and distributions. Which method better preserves the observed distribution, and what assumptions does it make?
3.4 Case Study: Preparing Data to Predict High Earners
We now bring together the data preparation ideas developed throughout this chapter in a more realistic case study. Unlike the controlled examples used earlier, this case study shows how several preparation tasks often arise together: recoding nonstandard missing-value codes, imputing missing entries in categorical features, simplifying sparse and high-cardinality categories, and inspecting potential outliers in skewed numerical variables.
The case study uses the adult dataset from the liver package. This dataset is widely used in machine learning as a benchmark for income prediction, but our focus here is not yet on model fitting. Instead, we prepare the data so that it can later be used in a principled and reproducible modeling workflow.
Problem Understanding and Dataset Overview
The prediction task in this case study is to determine whether an individual earns more than $50,000 per year based on demographic, educational, occupational, and financial characteristics. This type of question arises in applied settings such as economic research, policy analysis, and data-driven decision support. Here, however, the emphasis is on preparing the data for later modeling rather than fitting a predictive model.
The adult dataset was originally derived from data collected by the US Census Bureau. It contains information on individuals, including age, education, marital status, occupation, working hours, capital gains and losses, country of origin, and income category. In Chapter 12, we return to this dataset to construct and evaluate predictive models using decision trees and random forests (see Section 12.5).
We begin by loading the dataset from the liver package:
To inspect the dataset structure and variable types, we use the str() function:
str(adult)
'data.frame': 48598 obs. of 15 variables:
$ age : int 25 38 28 44 18 34 29 63 24 55 ...
$ workclass : Factor w/ 6 levels "?","Gov","Never-worked",..: 4 4 2 4 1 4 1 5 4 4 ...
$ demogweight : int 226802 89814 336951 160323 103497 198693 227026 104626 369667 104996 ...
$ education : Factor w/ 16 levels "10th","11th",..: 2 12 8 16 16 1 12 15 16 6 ...
$ education_num : int 7 9 12 10 10 6 9 15 10 4 ...
$ marital_status: Factor w/ 5 levels "Divorced","Married",..: 3 2 2 2 3 3 3 2 3 2 ...
$ occupation : Factor w/ 15 levels "?","Adm-clerical",..: 8 6 12 8 1 9 1 11 9 4 ...
$ relationship : Factor w/ 6 levels "Husband","Not-in-family",..: 4 1 1 1 4 2 5 1 5 1 ...
$ race : Factor w/ 5 levels "Amer-Indian-Eskimo",..: 3 5 5 3 5 5 3 5 5 5 ...
$ gender : Factor w/ 2 levels "Female","Male": 2 2 2 2 1 2 2 2 1 2 ...
$ capital_gain : int 0 0 0 7688 0 0 0 3103 0 0 ...
$ capital_loss : int 0 0 0 0 0 0 0 0 0 0 ...
$ hours_per_week: int 40 50 40 40 30 30 40 32 40 10 ...
$ native_country: Factor w/ 41 levels "?","Cambodia",..: 39 39 39 39 39 39 39 39 39 39 ...
$ income : Factor w/ 2 levels "<=50K",">50K": 1 1 2 2 1 1 1 2 1 1 ...The dataset contains 48598 observations and 15 variables. Most variables serve as predictors, while the target variable, income, indicates whether an individual earns more than $50,000 per year (>50K) or not (<=50K). The predictors include numerical features such as age, demogweight, education_num, capital_gain, capital_loss, and hours_per_week, as well as categorical features such as workclass, education, marital_status, occupation, relationship, race, gender, and native_country.
The dataset also includes demographic variables such as race, gender, and native_country. In applied prediction settings, the use of such variables requires careful ethical, legal, and contextual consideration. In this chapter, these variables are treated as part of a data preparation exercise, while broader questions about fairness, bias, and responsible modeling are revisited later in the book.
Practice: Use
str(adult)andsummary(adult)to inspect the dataset. Classify each variable as numerical, binary categorical, ordinal categorical, or nominal categorical. Then identify variables that may require preparation because of nonstandard missing-value codes, sparse categories, or strongly skewed numerical distributions.
Before modifying the data, we create a working copy:
adult_prepared <- adultThe object adult contains the original dataset loaded from the liver package, while adult_prepared will store the prepared version developed throughout this case study. This distinction keeps the preparation workflow transparent and allows us to return to the original data if needed.
The structure of the dataset provides the starting point for the preparation steps that follow. Several categorical variables require closer inspection for nonstandard missing-value codes, sparse levels, and possible category simplification. We begin by inspecting and recoding the nonstandard missing-value codes in adult_prepared so that R recognizes them as missing values.
Recoding Nonstandard Missing-Value Codes
The summary output reveals that three variables, workclass, occupation, and native_country, contain the value "?". In this dataset, "?" is not a meaningful category, but a nonstandard placeholder for missing information. Because R does not automatically treat this string as missing, we first recode it explicitly as NA in the working dataset adult_prepared.
adult_prepared[adult_prepared == "?"] <- NAThis command replaces all occurrences of "?" in adult_prepared with NA. The expression adult_prepared == "?" identifies the positions where the placeholder appears, and assigning NA to these positions ensures that R recognizes the affected entries as missing values in later analyses. The original adult dataset remains unchanged.
After recoding, we remove unused factor levels:
adult_prepared <- droplevels(adult_prepared)This step is useful because the placeholder "?" may remain as an unused factor level after being replaced by NA. Removing unused levels keeps the categorical variables cleaner and reduces the risk of complications in later preparation steps.
To assess the extent of missingness after recoding, we use the gg_miss_var() function from the naniar package:
library(naniar)
gg_miss_var(adult_prepared, show_pct = TRUE)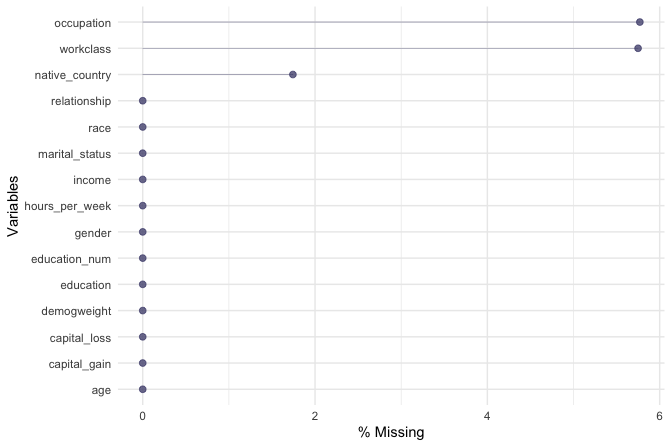
The plot confirms that missing values occur only in three categorical features: workclass with 5.75% missing, occupation with 5.77% missing, and native_country with 1.74% missing. These are the variables that require imputation in the next step. Recoding the placeholder values as NA has therefore made the missingness explicit and visible to R.
Imputing Missing Values in Categorical Features
Once the placeholder codes have been recoded as NA, we need to decide how to handle the missing entries. Removing all incomplete observations would discard information from otherwise usable records. Since the missing values occur only in categorical features, we use random sampling imputation to replace each missing value with a category drawn from the observed values of the same variable.
This approach preserves the empirical distribution of each categorical feature more directly than mode imputation, which would replace all missing entries with the most frequent category. However, random sampling imputation does not use information from other variables, such as age, education, occupation, or income. It should therefore be interpreted as a simple preparation step rather than as a recovery of the true missing categories.
We use the impute() function from the Hmisc package. Since random sampling is involved, we set a seed to make the results reproducible:
Each missing value is replaced by a value sampled from the observed categories of the corresponding variable. The imputation is carried out separately for workclass, occupation, and native_country, so the observed distribution of each feature is used for its own missing entries.
We then check that the imputation step has addressed all missing entries. The liver package provides the helper function find.na(), which reports missing values by variable:
find.na(adult_prepared)
[1] " No missing values (NA) in the dataset."The output confirms that no missing values remain in adult_prepared. At this stage, the categorical features workclass, occupation, and native_country are complete, although some of them still contain sparse or high-cardinality category structures. We address this issue in the next subsection.
Practice: Replace the random sampling imputation used above with mode imputation for
workclass,occupation, andnative_country. Compare the resulting category frequencies with those obtained using random sampling. How do the two imputation choices affect the distribution of these variables, and what implications might this have for downstream modeling?
Simplifying Sparse and High-Cardinality Categorical Features
Categorical variables with many levels can create sparse feature representations and make later modeling more difficult to interpret. This issue is especially relevant when some categories occur only rarely. In adult_prepared, the variable native_country contains many country labels, while workclass contains only a small number of levels but includes some rare categories. We simplify these variables to reduce sparsity while preserving interpretable information.
We begin with native_country, which contains 40 distinct country labels after missing values have been imputed. Treating each country as a separate category would increase the number of factor levels and, in models that require dummy variables, would increase the number of derived features. Since many countries occur infrequently, we group countries into broader geographic regions as a pragmatic preparation step.
This grouping should be interpreted as a modeling simplification rather than as a substantive statement about countries or individuals. The aim is to reduce sparsity and make the variable easier to use in later analyses.
We implement the grouping using the fct_collapse() function from the forcats package:
library(forcats)
Europe <- c("France", "Germany", "Greece", "Hungary", "Ireland", "Italy", "Netherlands", "Poland", "Portugal", "United-Kingdom", "Yugoslavia")
North_America <- c("United-States", "Canada", "Outlying-US(Guam-USVI-etc)")
Latin_America <- c("Mexico", "El-Salvador", "Guatemala", "Honduras", "Nicaragua", "Cuba", "Dominican-Republic", "Puerto-Rico", "Colombia", "Ecuador", "Peru")
Caribbean <- c("Jamaica", "Haiti", "Trinidad&Tobago")
Asia <- c("Cambodia", "China", "Hong-Kong", "India", "Iran", "Japan", "Laos", "Philippines", "South", "Taiwan", "Thailand", "Vietnam")
adult_prepared$native_country <- fct_collapse(
adult_prepared$native_country,
"Europe" = Europe,
"North America" = North_America,
"Latin America" = Latin_America,
"Caribbean" = Caribbean,
"Asia" = Asia
)We inspect the updated frequency table to verify the result:
table(adult_prepared$native_country)
Asia North America Latin America Europe Caribbean
1098 44601 1891 797 211We next simplify the workclass variable. Unlike native_country, this variable is not high-cardinality. Its main issue is that two levels, "Never-worked" and "Without-pay", occur rarely. Keeping these levels separate may add sparsity without providing a useful distinction for the preparation goals of this chapter. We therefore combine them into a broader category called "Not in paid employment":
adult_prepared$workclass <- fct_collapse(
adult_prepared$workclass,
"Not in paid employment" = c("Never-worked", "Without-pay")
)We again verify the recoding using a frequency table:
table(adult_prepared$workclass)
Gov Not in paid employment Private Self-emp
6918 32 35851 5797These recoding steps reduce sparsity in categorical variables while keeping the resulting categories interpretable. The grouped native_country variable now represents broad geographic regions rather than many sparse country labels, and the simplified workclass variable avoids retaining very rare employment categories as separate levels. These changes prepare the dataset for later modeling without yet applying model-specific encoding such as dummy variables or one-hot encoding.
Inspecting Outliers in Skewed Numerical Features
The earlier part of this chapter emphasized that outlier detection is a diagnostic step rather than an automatic cleaning rule. We now apply this idea to two numerical features in adult_prepared: capital_gain and capital_loss. These variables record annual capital gains and capital losses in US dollars. They are useful examples because they contain many zero values and a smaller number of relatively large positive values, a pattern that is common in economic and financial data.
A value of zero is meaningful here. It usually indicates that an individual did not report capital gains or losses in the relevant period. These zeros should therefore not be treated as missing values. At the same time, the positive values may appear as outliers because they are much larger than the mass of observations at zero. Before deciding how to handle them, we need to inspect whether they are plausible values or likely data errors.
We begin by inspecting summary statistics:
summary(adult_prepared[, c("capital_gain", "capital_loss")])
capital_gain capital_loss
Min. : 0.0 Min. : 0.00
1st Qu.: 0.0 1st Qu.: 0.00
Median : 0.0 Median : 0.00
Mean : 582.4 Mean : 87.94
3rd Qu.: 0.0 3rd Qu.: 0.00
Max. :41310.0 Max. :4356.00The summaries show that both variables have a minimum value of zero and a small number of much larger observations. For both variables, at least 75% of the observations are equal to zero, while the means are larger than the medians because of the positive values in the upper tail. This pattern indicates strong right skewness: most individuals report no capital gain or loss, while a smaller group report positive amounts.
To make this structure more visible, we examine the full distributions:
ggplot(data = adult_prepared) +
geom_histogram(aes(x = capital_gain), bins = 40) +
labs(title = "Capital gain", x = "Capital gain", y = "Count")
ggplot(data = adult_prepared) +
geom_histogram(aes(x = capital_loss), bins = 40) +
labs(title = "Capital loss", x = "Capital loss", y = "Count")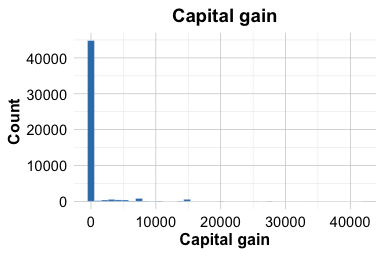
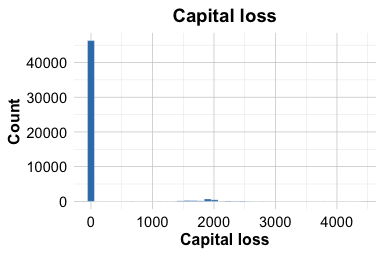
Both histograms show a large concentration at zero and a long right tail. This shape is not surprising for financial variables: many individuals report no capital gain or loss, while a smaller number report positive amounts. The large values are therefore candidates for closer inspection, not automatic removal.
To better understand the positive values, we inspect the distributions after excluding zeros:
adult_gain_nonzero <- subset(adult_prepared, capital_gain > 0)
adult_loss_nonzero <- subset(adult_prepared, capital_loss > 0)
ggplot(data = adult_gain_nonzero) +
geom_histogram(aes(x = capital_gain), bins = 30) +
labs(title = "Nonzero capital gain", x = "Capital gain", y = "Count")
ggplot(data = adult_loss_nonzero) +
geom_histogram(aes(x = capital_loss), bins = 30) +
labs(title = "Nonzero capital loss", x = "Capital loss", y = "Count")
The nonzero distributions show that the positive values are not isolated mistakes in the same sense as the impossible diamond dimensions examined earlier. They are unusual relative to the many zero values, but they remain plausible within the meaning of the variables. This distinction is important: an outlying financial value may represent a genuine event rather than a recording error.
Based on this inspection, we retain the observed values of capital_gain and capital_loss. Removing them would risk discarding relevant information about individuals with substantial financial gains or losses. If these variables later prove influential during modeling, several alternatives could be considered, such as applying a transformation, creating indicators for whether capital gain or loss is positive, or using modeling methods that are less sensitive to skewed numerical features.
For this chapter, the key preparation decision is therefore not to remove the large values, but to document their distribution and retain them for later modeling. This keeps the data faithful to the observed records while making the skewness and potential outliers visible for future analytical decisions.
Practice: Create binary indicators for whether
capital_gainandcapital_lossare greater than zero. Compare the frequency of positive values for the two variables. How might these indicators be useful in a later predictive model?
Prepared Dataset and Modeling Readiness
We have now completed the main data preparation steps for the adult dataset in this chapter. In the working dataset adult_prepared, nonstandard missing-value codes have been recoded as NA, missing categorical values have been imputed, sparse and high-cardinality categorical features have been simplified, and skewed financial variables have been inspected rather than automatically modified or removed.
Before moving on, we check that the prepared dataset no longer contains missing values. The liver package provides the helper function find.na(), which reports missing values by variable:
find.na(adult_prepared)
[1] " No missing values (NA) in the dataset."The output confirms that the missing values introduced by the "?" placeholders have been addressed. The dataset is now more coherent and better documented than the original version. However, it is important to distinguish between a generally prepared dataset and a dataset that is fully ready for a specific modeling algorithm. The steps in this chapter focus on general data preparation: making missingness explicit, handling incomplete values, simplifying categorical structure, and inspecting unusual numerical values.
Further modeling-specific preparation may still be required. For example, algorithms that require numerical input may need categorical variables to be encoded as dummy variables or one-hot indicators. Distance-based methods may require feature scaling, while tree-based methods can often handle unscaled numerical variables more naturally. In addition, train-test partitioning, cross-validation, and leakage-aware preprocessing should be carried out as part of the data setup for modeling discussed in Chapter 6.
The object adult_prepared therefore represents the output of the data preparation work completed in this case study. It is suitable for exploratory analysis and provides a coherent starting point for later modeling. In Chapter 12, we return to this prepared income-prediction problem when fitting and evaluating decision tree and random forest models.
3.5 Chapter Summary and Takeaways
This chapter introduced data preparation as a set of practical and analytical decisions that shape the quality of later analysis and modeling. Using the diamonds and adult datasets, we examined how raw data can contain implausible measurements, nonstandard missing-value codes, sparse categories, and strongly skewed numerical features. The goal was not simply to make the data look cleaner, but to make preparation choices that are transparent, defensible, and aligned with the purpose of the analysis.
A central theme was the importance of distinguishing between superficially similar problems. We distinguished outliers from invalid values: an unusual observation may be rare but meaningful, while an impossible value, such as a zero physical dimension for a diamond, should be treated as a data-quality problem. We also distinguished genuine missing values from placeholder codes such as "?", which must first be recoded as NA before R can recognize them as missing.
The chapter also compared several approaches to imputation. Deterministic methods such as mean, median, and mode imputation are simple and reproducible, but they replace missing entries with repeated values and may reduce variability. Random sampling imputation preserves the marginal distribution more directly, but it does not use relationships with other variables. Model-based and multiple imputation methods can use more information, but they require stronger assumptions and more careful implementation.
Finally, we considered categorical feature simplification as a trade-off. Grouping sparse or high-cardinality categories can reduce complexity and improve interpretability, but it may also remove information if categories with distinct meanings are combined too aggressively. The adult case study illustrated how such decisions should be documented and interpreted as preparation choices rather than automatic corrections.
Together, these ideas prepare the ground for the next stage of the Data Science Workflow. In the next chapter, we turn to exploratory data analysis, using visualizations and numerical summaries to investigate patterns, relationships, and potential signals in prepared data.
3.6 Exercises
The exercises in this chapter reinforce the main ideas of data preparation through conceptual questions, focused practice, and an applied mini-project. They emphasize the distinction between unusual and invalid values, the recognition of missing values and placeholder codes, the choice of imputation strategies, and the trade-offs involved in simplifying categorical variables. The final exercises ask you to reflect on reproducibility, leakage, fairness, and the role of data preparation in responsible modeling.
Conceptual Understanding
Explain the difference between continuous numerical variables, discrete numerical variables, ordinal categorical variables, and nominal categorical variables. Give one example of each.
Explain how the
typeof()andclass()functions differ in R. Why can both be useful when preparing data for analysis or modeling?Distinguish between an outlier and an invalid value. Give one example of an unusual but valid value and one example of a value that should be treated as a data-quality problem.
Explain the difference between a missing value and a placeholder code. Why should values such as
"?","unknown",999, or-1be inspected before being recoded asNA?Compare deterministic imputation methods, such as mean, median, or mode imputation, with stochastic methods such as random sampling imputation. Why is
set.seed()important when using stochastic imputation?Explain the difference between an imputation method that preserves the marginal distribution of one variable and a method that uses relationships among variables. Give one example of each type.
Explain why imputing missing values before a train-test split can lead to data leakage. How should imputation be handled in a predictive modeling workflow?
Category simplification can reduce sparsity but may also remove information. Explain this trade-off using an example from a categorical variable with many rare levels.
Hands-On Practice: Data Preparation with diamonds
Load the
diamondsdataset and classify its variables as numerical, ordinal categorical, or nominal categorical. Compare your classification with the output ofstr().Use
summary()to inspect the variablesx,y, andz. Which values appear physically implausible, and why?Create histograms and boxplots for
x,y, andz. Use these plots to distinguish between values that are merely unusual and values that are likely invalid.Recode physically implausible values in
x,y, orzasNAusing a clearly documented rule. Compare the summary statistics before and after recoding.After recoding implausible values in one of the dimension variables as
NA, apply both median imputation and random sampling imputation. Useset.seed()for the random sampling method and compare the resulting summaries.Create a new variable representing diamond volume using
x * y * z. Summarize and visualize this variable before and after handling implausible dimension values. What changes do you observe?Create a scatter plot of
caratversusprice. Discuss how invalid dimension values or extreme observations could affect interpretation of this relationship.
Hands-On Practice: Data Preparation with adult
Load the
adultdataset from the liver package and create a working copy calledadult_prepared. Classify the variables as numerical, binary categorical, ordinal categorical, or nominal categorical.Identify variables that contain the placeholder code
"?". Recode these values asNAinadult_preparedand verify the missing-value pattern usingfind.na()or another suitable function.Impute the missing values in
workclass,occupation, andnative_countryusing two methods: replacing missing values with the most frequent category and using random sampling imputation. Compare the resulting frequency tables.Combine the rare
workclasslevels"Never-worked"and"Without-pay"into a broader category. Propose an appropriate label and justify your choice.Compare two strategies for simplifying
native_country: grouping countries into broad geographic regions and grouping rare countries into an"Other"category while keeping frequent countries separate. Discuss the trade-off between reducing sparsity and preserving information.Inspect the distributions of
capital_gainandcapital_lossusing summaries and histograms. Explain why zero values should not be treated as missing values in these variables.Create binary indicators for whether
capital_gainandcapital_lossare greater than zero. Summarize these indicators by income group and interpret the results.The
adultdataset includes demographic variables such asrace,gender, andnative_country. Discuss why the use of these variables in income prediction requires ethical, legal, and contextual consideration.
Applied Challenge: Data Preparation with house_price
Load the
house_pricedataset from the liver package. Create a brief data audit that identifies the response variable, numerical predictors, categorical predictors, and variables with missing values.Select three variables with missing values. For each variable, describe a plausible reason why the values may be missing and suggest an appropriate handling strategy.
Use histograms, boxplots, or scatter plots to inspect
SalePriceandGrLivArea. Identify any extreme observations and discuss whether they appear to be data errors or meaningful high-value properties.Choose two variables that may benefit from transformation or grouping, such as a skewed numerical variable or a categorical variable with many levels. Apply your chosen preparation steps and justify them.
Write a short preparation plan for using
house_pricein a predictive modeling task. Your plan should explain which steps should be performed before the train-test split and which steps should be learned from the training set only to avoid leakage.
Reflection and Responsible Data Preparation
Explain how your approach to handling outliers might differ between patient temperature data, income data, and house price data.
Discuss how data preparation choices, such as grouping categories, imputing missing values, or removing extreme observations, can influence the fairness and interpretability of a predictive model.
Summarize the most important lesson you learned from this chapter. How will it change the way you inspect and prepare raw data in future analyses?